
MiniGPT-4をAutoGPTQ/BitsAndBytesで量子化時の生成文章の定量評価


LLMをデプロイする際に、LLM部分の量子化が必要になることが多いです。MiniGPT4のようなVLMに焦点をあて、AutoGPTQとBitsAndBytesという2つの量子化フレームワークに対し、生成文章の定量評価を行います。「評価指標はそもそも信頼できるのか」という問いから入るので、かなり注意深い検討が必要です。
目次
はじめに
以下の記事で、Vision & Language Model(VLM)の量子化について、llama.cppのAutoGPTQとBitsAndBytesの速度面を検証しました。
- LLaMA.cpp+(cu)BLASのCPU/GPUのスループット検証(ローカル編)
- LLaMA.cpp+(cu)BLASのCPU/GPUのスループット検証(AWS編)
- MiniGPT4をAutoGPTQ/BitsAndBytesで量子化してAWS上でのスループットを検証する
今回は生成される文章を定量評価していきたいと思います。具体的にはBitsAndBytesとAutoGPTQのどちらが良いのかという点です。
AutoGPTQとBitsAndBytesは根本的に異なるもので、BitsAndBytesはただ演算性能を落とすものに対し、AutoGPTQが量子化に訓練データを必要とするものです。うまく使えばAutoGPTQのほうがよくなる可能性はありますが、コントロールするパラメーターが広くなるので「BitsAndBytesよりよいのか」という点が難しくなります。ちなみに速度面では、過去の記事からわかったことは、「AutoGPTQは速度面では明らかに良い」です。今回はAutoGPTQの生成文章を見ていきたいと思います。
生成クォリティの検討は難しくて、「評価指標がそもそも信頼可能性がある」という点を考慮する必要があります(速度の場合は単純にtoken per secondが高ければ良いでOKでした)。かなり注意深い検討が必要な内容です。長めの内容になりますが、仮説検証ベースで進めていきます。
先に結論
長いので先に結論を示します。
- 評価指標について
- LLMの量子化を計測する際の評価指標は、Embeddingの距離で良い
- 距離関数はL1ロスやコサイン距離が考えられるが、サンプル単位のL1ロスでいい。量子化同士の比較、Ground Truthとの比較の両方で使える
- Embeddingのバックボーンのモデルは絶対的に良いのはないが、FlanT5、OpenAI Embedding、Universal sentence encoderどれを使っても出た。ただそれぞれに癖があるので、複数組み合わせるのが良さそう
- GPTのゼロショットの評価は、正確性と創作性のトレードオフを見たいときは便利な可能性があるが、量子化の評価を見たいときは別にこれを使わなくても良い。
- 量子化について
- AutoGPTQで量子化するなら、良質なデータセットを使うと、性能がスケールする。つまり、量子化に使うサンプル数を増やしたときに、量子化性能が良くなる。
- ここで使うデータセットは、普通のLLMのInstruction Tuningのデータセットで良い(VLMのデータでなくても、BitsAndBytesと同程度の性能は出せた)。VLMのInstruction Tuningのデータセットでなくて良い
- AutoGPTQは、良質なデータセットを量子化時に多く食わせるとBitsAndBytesよりも性能的に良くなる可能性があるが、ここの条件を誤ると逆に悪化することも多い。
- 良質なデータセットとは、例えばalpaca_data_cleanedのようなものである。以下の条件が量子化時の良質なデータセットの良い条件ではないか
- 文章そのものがノイジーではない
- 記述されているInstructionが広範囲な内容である
- 記述されているドメインが広範囲な内容である
- その他
- LLaMA2の強さや、データセット間の得意不得意が定量的に示せた
評価データセットと評価モデル
評価モデル
MiniGPT-4より、公開されている3モデルを使用
- minigpt4_llama2_7b
- minigpt4_vicuna_7b
- minigpt4_vicuna_13b
評価データセット
以下の4データで検証しました。
M3ITの3データは、データ数が多すぎるのでValidationデータをベースに、500データまで減らして使います。
量子化のパターンごとの比較になることが多いので、3モデル×4データセット=12パターンが基本的な評価になります。この中での勝率を仮説検証の中でのKPIとしています。
量子化方法
基本的な量子化方法は、AutoGPTQ、BitsAndBytesの2種類を使いました。
AutoGPTQでは量子化に使うデータセット、データセットの使用量がハイパーパラメータになります。データセットの使用量とは、量子化でどの程度データを使うかを示します。128、1024の2パターンを試しました。多いほど量子化の精度は良くなるはずです(反面量子化処理は時間かかります)。ビット数は4bitで固定しました。これは前回のスループットの検証で、4bitが最もコスパが良かったからです。
- AutoGPTQ
- alpaca_data_cleaned.json
- 元はAutoGPTQの付属でついていたもの
- https://github.com/PanQiWei/AutoGPTQ/tree/main/examples/quantization/dataset
- databricks-dolly-15k
- https://huggingface.co/datasets/databricks/databricks-dolly-15k
- これをalpaca_data_cleaned.jsonのフォーマットに変換して使用
- alpaca_data_cleaned.json
BitsAndBytesでは、量子化の条件のみ変わります。
BitsAndBytes/AutoGPTQについて、条件を変えて6パターン用意しました。
- AutoGPTQ
- alpaca_data_cleaned.json / 使用サンプル数128
- alpaca_data_cleaned.json / 使用サンプル数1024
- databricks-dolly-15k / 使用サンプル数128
- databricks-dolly-15k / 使用サンプル数1024
- BitsAndBytes
- 4bit
- 16bit (FP16、量子化なし)
仮説検証の流れ
例えば、「同一条件で量子化方法を見たときに、FP16が最も評価指標がよくなるはずだ」という仮説を立てたとします。このとき以下のような比較をします。
| metrics | distance | win | win_rate |
|---|---|---|---|
| 評価指標1 | cosine | 4 | 33.3% |
| 評価指標1 | L1 | 3 | 25.0% |
| 評価指標2 | cosine | 4 | 33.3% |
| 評価指標2 | L1 | 0 | 0.0% |
縦軸は「評価指標×距離関数」とします。Winは「立てた仮説を評価指標が満たした回数」を意味します。例えば、「FP16が最も評価指標がよくなるはずだ」という仮説を立てた場合は、FP16が最も評価指標が良くなったケースの数を数えます。
このケースの分母はどこかというと、「データセット×モデル」の12パターンです。先程「12パターンが基本的な仮説検証の1セットになる」と説明したのはここです。
「評価指標は1つでいいやん」と思うかもしれませんが、LLM(VLM)の評価はかなり難しくて、「これなら一発で評価できる」という打ち出の小槌のモデルが存在しないことです(打ち出の小槌があれば、それをLLMの損失関数に組み込めばいいという話になります)。よく行われるのはヒューマンフィードバックですが、これも大変です。似たような話は画像生成でも古くからありますが、画像生成の場合はFIDにようにEmbeddingベースの距離を取ることである程度人間の主観評価を代替できることがわかっているので、今回もその思想を引き継ぎます。
評価指標
評価指標の定義
以下の2つの系統、合計4つの評価指標を用いました。
- Embeddingベース
- FlanT5-base(google/flan-t5-base)からSentence Embeddingを計算し、2つの文章のEmbeddingの距離を計算する
- OpenAIのEmbedding API(Ada v2)を使い、2つの文章のEmbeddingの距離を計算する
- Universal Sentence Encoder(sentence-transformers/use-cmlm-multilingual)を使い、2つの文章のEmbeddingの距離を計算する
- LLMのゼロショットベース
- GPT3.5-Turboに質問と回答2つ(Answer A、Answer B)を与えてA/Bテストさせる。Aが勝った割合を計算する。その上で、「(Aが勝った割合-0.5)の絶対値」と評価指標とする。これは勝率50%=Evenであり、Evenのときに評価指標が0になってほしいため。
- 本当はGPT-4でやるべきだが、APIが高すぎるのでGPT-3.5-turbo-0613で代用。
距離関数は、コサイン距離、L1距離の2パターンを試します。サンプル間の距離の集約計算は平均を用います(中央値と大して差がなかったため)
評価指標の生データはかなり広大なので、仮説検証ベースで行います。
量子化前後、Ground Truthとの比較
各評価で比較する2つの文章とは以下の2パターンからなります。
- 量子化後の推論結果vs 量子化前(FP16)の推論結果
- 量子化前後の結果を比較します。量子化(例えば、AutoGPTQやBitsAndBytes)をかけたあとの文章が、量子化前(FP16)と比べてどれだけ劣化したかを定量評価します。理論的にはFP16のほうが常によくなるはずです。またFP16 vs FP16はEvenはずです。
- 量子化前後の推論結果 vs Ground Truthの値
- 各質問にはGround Truthの答えがあるのでそれを比較します。FP16 vs GT、AutoGPTQ 4bit vs GT、BNB 4bit vs GTのように評価します。
距離関数と集約計算
Embeddingの場合は、量子化前後の生成テキストに対し、(サンプル数, 次元数)という値が返ってきます。このときどの距離関数を使うかが問題になります。ここでは2つの距離関数を使います
- コサイン距離:1-コサイン類似度です
- L1距離:次元ごとのL1距離を計算し、平均をとったものです。マンハッタン距離ともいいます。
それぞれ以下の関数で計算しました。
from sklearn.metrics.pairwise import paired_cosine_distances, paired_manhattan_distances
サンプル間の集約は平均(Mean)を用いました。中央値(Median)でやってもたところ「どっちでもいいじゃん」となったので、ここはこだわらないことにしました。
LLMのプロンプト
LLMのゼロショットベースは以下のプロンプトからなります。
from langchain.schema import SystemMessage, HumanMessage
messages = [
SystemMessage(content="""Choose the better of the two answers "A" and "B" corresponding to the following Input.
Answer "A" or "B" for the better one, or answer "Even" if you cannot decide."""),
HumanMessage(content=f"""# Input
{question[question_key]}
# A
{answer_quant["response"]}
# B
{answer_quant["gt_answer"] if mode_gt else answer_fp16["response"]}
""")]
A/Bではあるのだが、「どっちとも言えないときはEvenと答えろ」という逃げ道も残しておきます。Aが勝ったときは1、EvenのときはAに0.5を加算します。
A/Bテストの場合は、距離や集約の概念が出てきません。
立てた仮説
以下のような仮説を立てました。大きな流れとしては「評価指標の妥当性」→「量子化についての仮説」です。
評価指標の妥当性
まず、どの評価指標が尺度として正しいのか、最も使い物になるのかがよくわからなかったので、これを理詰めで確かめていきます。評価指標は距離ベース(やそれに類するもの)なので低いほうが良いです。
- 仮説E1:量子化vsfp16を比較したときに、fp16 vs fp16が距離最小値となるはずだ
- 距離最小値=最も評価指標が良い
- これは当たり前の話で、同一のものを比較しているのだから、評価指標が最も良くなるべきです
- 仮説E2:量子化vsfp16を比較したときに、fp16 vs fp16が全体の最小値の1.05倍以内に入っているはずだ
- 仮説E1より弱い仮説で、曖昧さを許容します。全体というのは量子化条件(6パターン)をパイとしたときの全体です。
- 仮説E3:量子化vsGTを比較したときに、fp16 vs GTが距離最小値となるはずだ
- GT = Ground Truth
- 仮説E1をGTと比較した場合です。ただ、GTが本当にGTと扱っていいのかはデータセットの質によって変わるため、仮説E1よりは曖昧な仮説になります(例:今回は使っていないですが、COCOの場合はGTが短文すぎるため、LLMの長文出力とは毛色が変わります)
- 仮説E1よりは自明ではない仮説です
- 仮説E4:量子化vsGTを比較したときに、fp16 vs GTが全体の最小値の1.05倍以内に入っているはずだ
- 仮説E3に対し、曖昧さを許容した弱い仮説です
- 仮説E5:GTとの距離が最小なケースでは、fp16との距離も最小になるはずだ
- 仮説E1とE3の整合性についての仮説です
- 仮説E6:GPTのゼロショットの評価と、Embeddingの距離の評価には一定の相関が認められるはずだ
量子化についての仮説
どのような評価指標がよいかを検討した上で、以下の内容を検証します。
- 仮説Q1:AutoGPTQでは量子化の使用データ量が128より、1024のほうがよくなるはずだ
- AutoGPTQでは、量子化に使用するデータセットを選べます
- ここでは付属のalpaca_data_cleaned.jsonとdolly-15kを使い、量子化に使用するデータ量を128と1024と変えて検証します
- データ量が多いほどノイズが減るのでおそらく性能が良くなるはずです
- 仮説Q2:AutoGPTQでは量子化に使うデータセットは、dollyよりalpacaのほうがよくなるはずだ
- 仮説Q3:AutoGPTQは量子化条件によっては、BitsAndBytesより常に良くなることがあるはずだ
- AutoGPTQのalpacaで1024のように、強い条件でやったらBitsAndBytesを上回るんじゃない?という点
- 速度の点ではAutoGPTQのほうが速いので、性能も上回ったら嬉しい
評価指標の妥当性の検証
仮説E1:量子化vsfp16を比較したときに、fp16 vs fp16が距離最小値となるはずだ
- 距離最小値=最も評価指標が良い
- これは当たり前の話で、同一のものを比較しているのだから、評価指標が最も良くなるべきです
| metrics | distance | win | win_rate |
|---|---|---|---|
| flant5 | cosine | 12 | 100% |
| flant5 | l1 | 12 | 100% |
| gpt3.5-turbo | score | 4 | 33% |
| openai | cosine | 12 | 100% |
| openai | l1 | 12 | 100% |
| sentence | cosine | 12 | 100% |
| sentence | l1 | 12 | 100% |
Embeddingベースは常にこの仮説を満たしました(このケースだけ距離0になるので当たり前ですね)。
GPT3.5のゼロショットは勝率が低いです。これはGPT自体にブレがあるので致し方ないでしょう。
仮説E2:量子化vsfp16を比較したときに、fp16 vs fp16が全体の最小値の1.05倍/1.1以内に入っているはずだ
- 仮説E1より弱い仮説で、曖昧さを許容します。全体というのは量子化条件(6パターン)をパイとしたときの全体です。
仮説E1でEmbeddingベースはもうこれを満たすことがわかっているので、GPT3.5のみ調べます。
| metrics | distance | ratio | win | win_rate |
|---|---|---|---|---|
| gpt3.5-turbo | score | 1.05 | 4 | 33% |
| gpt3.5-turbo | score | 1.1 | 4 | 33% |
曖昧さを1.1倍まで許容してもGPT3.5の勝率は改善しませんでした。GPTのゼロショットはこういう理論的な厳密性を求めたいときは厳しそうです。
仮説E3:量子化vsGTを比較したときに、fp16 vs GTが距離最小値となるはずだ
- GT = Ground Truth
- 仮説E1をGTと比較した場合です。ただ、GTが本当にGTと扱っていいのかはデータセットの質によって変わるため、仮説E1よりは曖昧な仮説になります(例:今回は使っていないですが、COCOの場合はGTが短文すぎるため、LLMの長文出力とは毛色が変わります)
- 仮説E1よりは自明ではない仮説です
| metrics | distance | win | win_rate |
|---|---|---|---|
| flant5 | cosine | 2 | 17% |
| flant5 | l1 | 3 | 25% |
| gpt3.5-turbo | score | 3 | 25% |
| openai | cosine | 3 | 25% |
| openai | l1 | 2 | 17% |
| sentence | cosine | 3 | 25% |
| sentence | l1 | 3 | 25% |
勝率は仮説E1と比べてかなり落ちました。
この理由について補足すると、LLMのようなキャプション生成の場合のGround Truthというのは扱いがかなり難しいからです。「Answer is ◯◯」のようにスパッというような例がGround Truthとしてついてたとしても、実際のLLMの出力が「Answer is ◯◯. Because…」のように長々と生成してしまうケースが多々あるためです。
つまり、「Ground Truthが本当にGround Truthといっていいいのかわからない」という問題があります。
仮説E4:量子化vsGTを比較したときに、fp16 vs GTが全体の最小値の1.05/1.1倍以内に入っているはずだ
- 仮説E3に対し、曖昧さを許容した弱い仮説です
| metrics | distance | win | win_rate |
|---|---|---|---|
| flant5 | cosine | 7 | 58% |
| flant5 | l1 | 11 | 92% |
| gpt3.5-turbo | score | 4 | 33% |
| openai | cosine | 10 | 83% |
| openai | l1 | 11 | 92% |
| sentence | cosine | 7 | 58% |
| sentence | l1 | 11 | 92% |
5%ぐらいまで曖昧さを許容すると、特にL1ベースで良くなりました。おそらくL1のほうがスケールが大きくなりやすいから(コサイン距離は0-1の値域、L1距離は20ぐらいある)だと思われます。
曖昧さを1.1倍まで許容した場合は以下のようになります。
| metrics | distance | win | win_rate |
|---|---|---|---|
| flant5 | cosine | 9 | 75% |
| flant5 | l1 | 12 | 100% |
| gpt3.5-turbo | score | 4 | 33% |
| openai | cosine | 11 | 92% |
| openai | l1 | 12 | 100% |
| sentence | cosine | 10 | 83% |
| sentence | l1 | 12 | 100% |
L1のEmbeddingベースではすべて仮説を満たせるようになりました。コサインもかなり満たしていますね。
仮説E5:GTとの距離が最小なケースでは、fp16との距離も最小になるはずだ
- 仮説E1とE3の整合性についての仮説です
少しわかりづらいので細くしておくと、
- AutoGPTQ
- alpaca / 128
- alpaca / 1024
- dolly / 128
- dolly / 1024
- BNB
- 4bit
- FP16
ように量子化のケースが6個あります。各ケースについて、「量子化 vs FP16」「量子化 vs GT」のように計算し、それぞれの指標を$Q_i, G_i$とします。このとき、
$$\arg\min{Q_i}=\arg\min{G_i}$$
となったケースの数の合計です(これをモデル×データセットの12パターンで回します)。
| metrics | distance | win | win_rate |
|---|---|---|---|
| flant5 | cosine | 2 | 17% |
| flant5 | l1 | 3 | 25% |
| gpt3.5-turbo | score | 5 | 42% |
| openai | cosine | 3 | 25% |
| openai | l1 | 2 | 17% |
| sentence | cosine | 3 | 25% |
| sentence | l1 | 3 | 25% |
結果はなんともいえない感じになりました。あまりこのへんの整合性は求められないよという感じでしょうか。
ただ、GPT3.5がこの点では最も良かったのは興味深い点です(この場合、Questionが与えられてアラインメントがとれるから?)
仮説E6:GPTのゼロショットの評価と、Embeddingの距離の評価には一定の相関が認められるはずだ
相関分析
これはなんとくのものですが、GPTの評価とEmbeddingの距離の評価は一定の相関があるのかなと思って調べました。
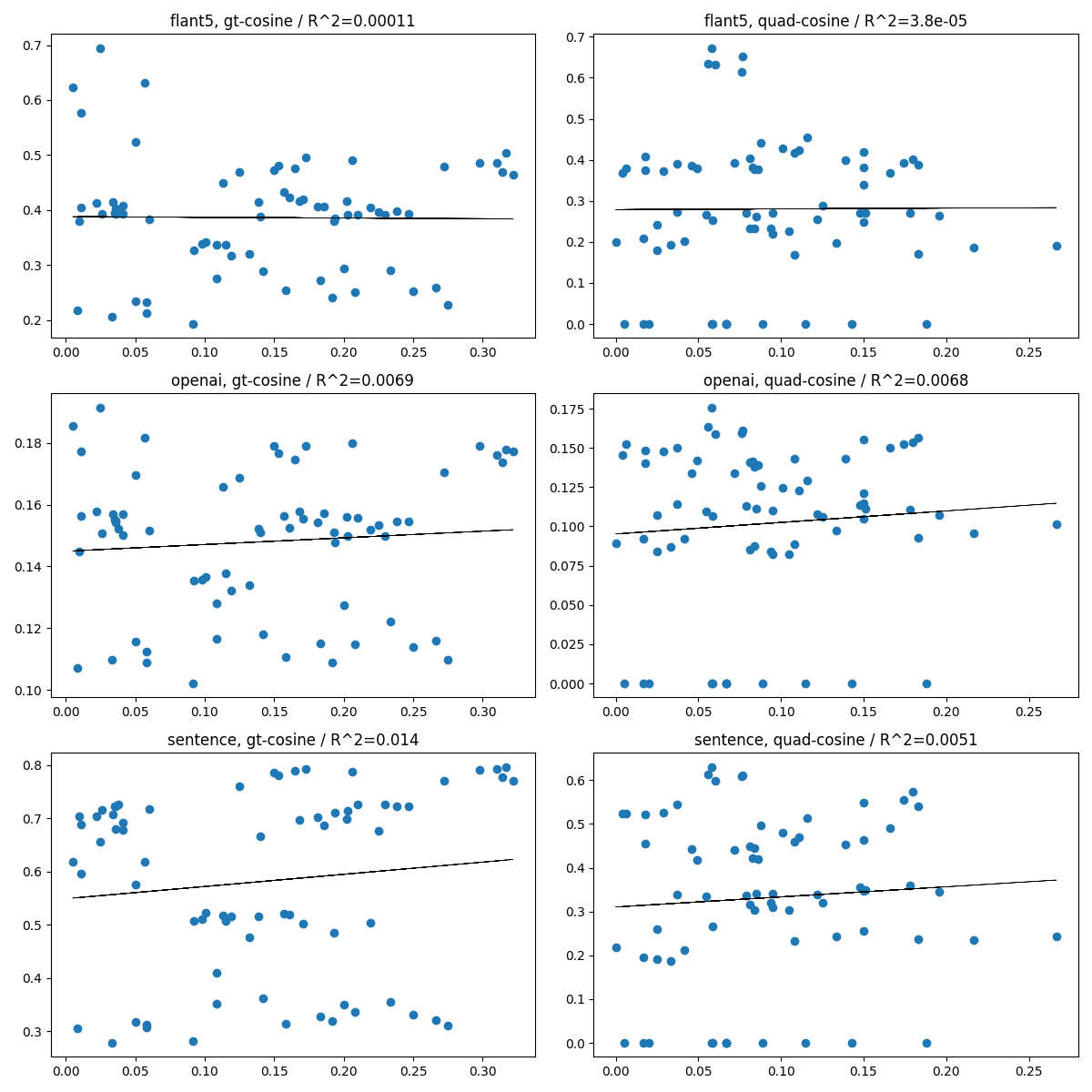
横軸はGPTのゼロショットの評価(A/BテストでAが良かった比率を0.5から引いた絶対値)で、縦軸は各距離ベース(コサイン距離/L1距離)の評価です。
コサイン距離の場合
L1距離の場合
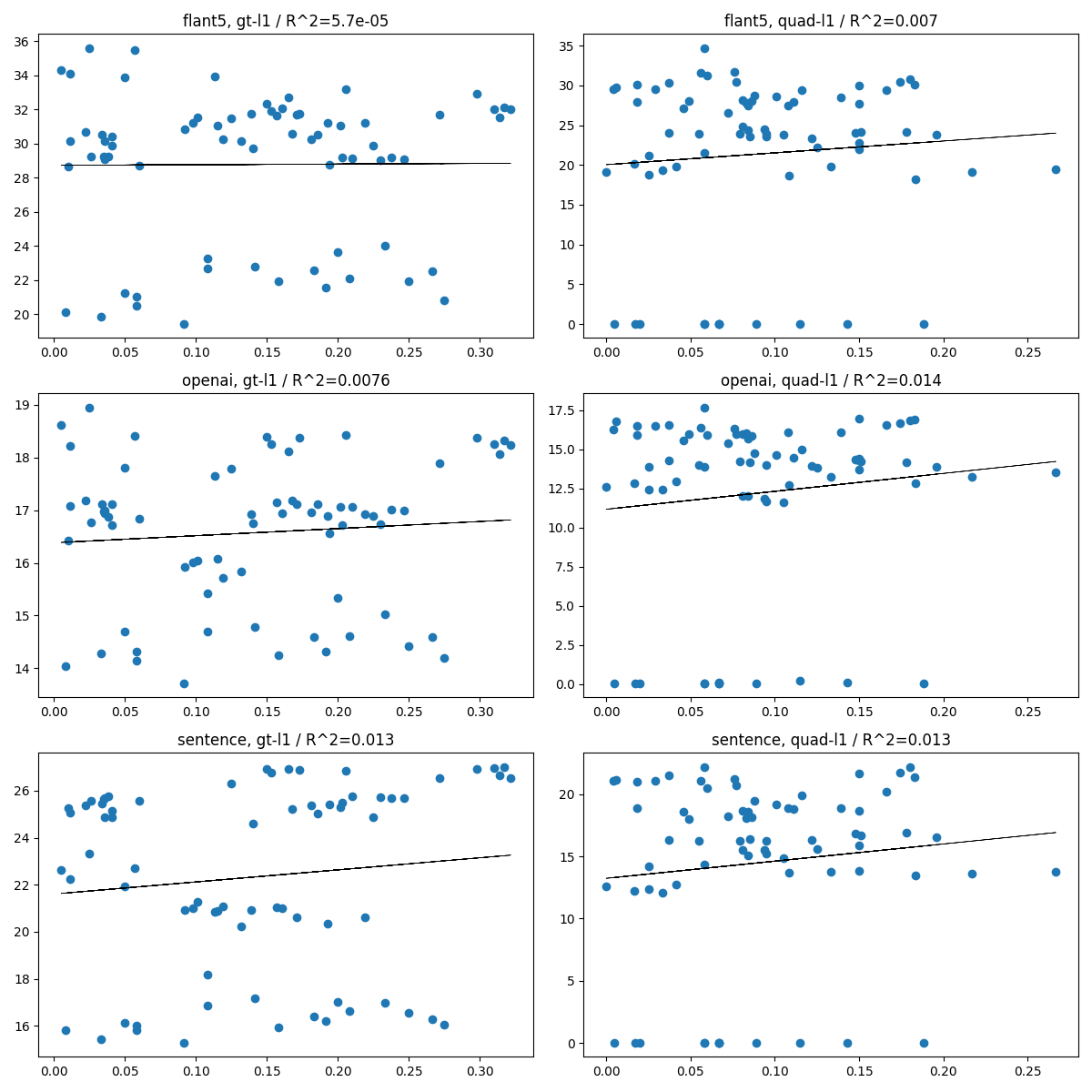
横軸は0に近づくほど差がなくなり、縦軸も0に近づくほど良くなるので、一定の相関があるかと思いましたが、全く相関なかったといえるかもしれません。
分布の分析
しかし、ここで気になるのが特にL1の場合、プロットの中に塊の分布がいくつか見受けられることです。これが推論データセット依存のものか、評価関数依存のものか気になります。
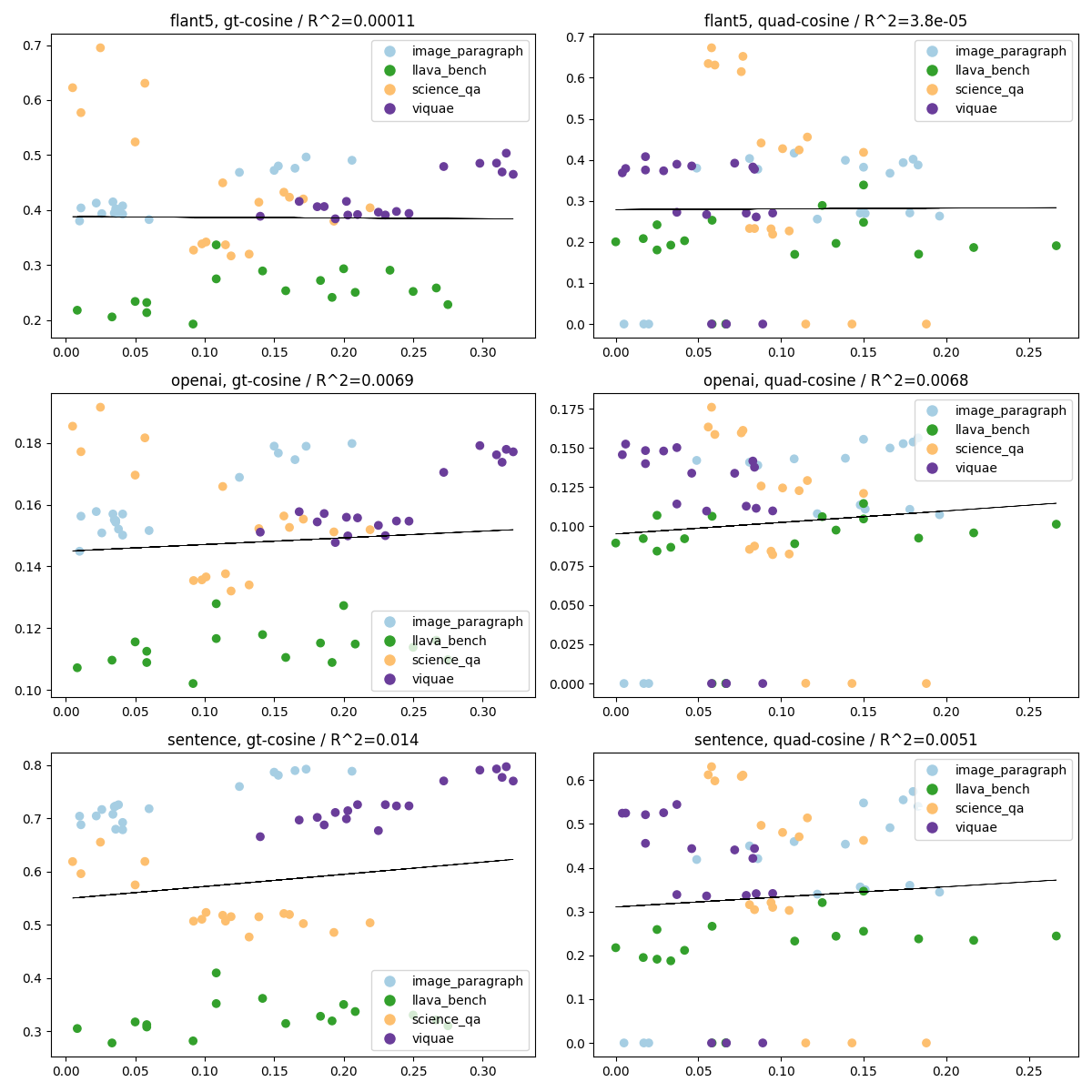
そこで、同様のプロットを、データセット別にマーキングして見てみます。
コサイン距離の場合
L1距離の場合
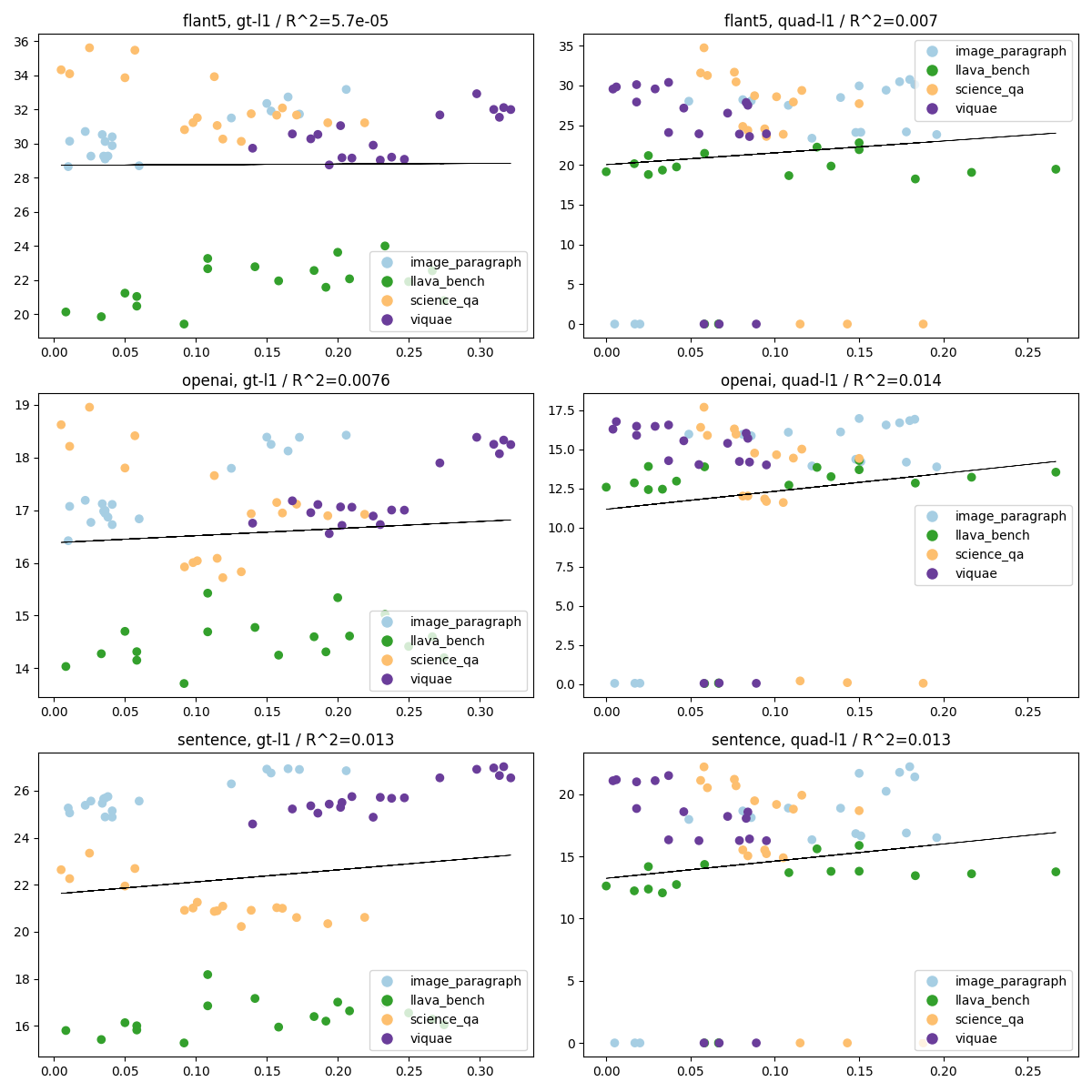
これを見ると、データセットごとにGPTとEmbeddingの結果に相関はある程度あるが、必ずしも正の相関になるとは限らないということです。
これはどういうことかというと解釈がむずいですが、どの程度正確性の担保が大事なのか、創作性の担保が大事なのかによるのではないかと考えられます。science_qaのように、正確性が大事なデータセットの場合だと、GPTが良いと判断した結果はEmbeddingでは結構遠いものであることがわかり、ある程度創作が入ってるもののほうがGPTは良いと判断していると思われます。Embeddingでは近いもの(正確性の高いもの)は、あまりGPTは良いと判断していないと考えられます。
つまり、GPTの結果とEmbeddingの結果がどの程度によるかはデータセット依存という結論になります。
ちなみに、右のquad(量子化した場合)で、y軸の値が0に張り付いているのは異常値ではなく、FP16の場合の結果です。
どの評価指標が良いか
正直この中からどの評価指標が良いかを選ぶのは難しいです(正直どれでもいいのではないか感はかなりあります)。
ただ、コサインかL1は選べそうで、L1のほうが良いと思います。なぜかというと仮説E1、E4でL1のほうが素直な結果になったこと。またE6のデータセットごとのプロットを見たときにL1のほうがある程度まとまりをもった結果になっていること(Quadの場合はグラフの錯覚の可能性はありますが)が理由です。
その上で、FlanT5が良いか、Sentece(Universal sentence encoder)が良いか、OpenAI Embeddingが良いかはかなり悩ましくて「どれでも良いのではないか」と思われます。なので、この3つのL1に絞って検証していきたいと思います。
また、GPT3.5の結果は、ある程度有意義性は感じられるものの、「どの量子化フレームワークが良いか」の判断にはやや外れた傾向が見られるため今回は除外します。正確性が良いのか、創作性が良いのかを求めたいときは便利ではないかと思います。
量子化についての仮説の検証
仮説Q1:AutoGPTQでは量子化の使用データ量が128より、1024のほうがよくなるはずだ
- AutoGPTQでは、量子化に使用するデータセットを選べます
- ここでは付属のalpaca_data_cleaned.jsonとdolly-15kを使い、量子化に使用するデータ量を128と1024と変えて検証します
- データ量が多いほどノイズが減るのでおそらく性能が良くなるはずです
| metrics | target | dataset | win | win_rate |
|---|---|---|---|---|
| flant5 | gt | alpaca | 9 | 75% |
| flant5 | gt | dolly | 7 | 58% |
| flant5 | quad | alpaca | 9 | 75% |
| flant5 | quad | dolly | 5 | 42% |
| openai | gt | alpaca | 9 | 75% |
| openai | gt | dolly | 3 | 25% |
| openai | quad | alpaca | 8 | 67% |
| openai | quad | dolly | 5 | 42% |
| sentence | gt | alpaca | 7 | 58% |
| sentence | gt | dolly | 7 | 58% |
| sentence | quad | alpaca | 6 | 50% |
| sentence | quad | dolly | 4 | 33% |
結果はこの通りで、基本的には1024のほうが良くなるが、alpacaでは顕著に現れるのに対してdollyではそこまで効果がないということがわかりました。
量子化に使用するデータを128vs1024でみたときに、alpacaの勝率は50%以上のものが大半で、多くは75%ぐらいあります。しかし、dollyは微妙です。この理由は、dollyのデータセットを見たときに思ったのですが、データセットがノイジーだからというのが理由にあるのではないかと考えられます。alpaca_cleanedはかなりきれいな英語だったため、量子化に使うデータセットの質が大事ではないかと思われます。
仮説Q2:AutoGPTQでは量子化に使うデータセットは、dollyよりalpacaのほうがよくなるはずだ
| metrics | target | quant_size | win | win_rate |
|---|---|---|---|---|
| flant5 | gt | 128 | 5 | 42% |
| flant5 | gt | 1024 | 7 | 58% |
| flant5 | quad | 128 | 6 | 50% |
| flant5 | quad | 1024 | 10 | 83% |
| openai | gt | 128 | 3 | 25% |
| openai | gt | 1024 | 6 | 50% |
| openai | quad | 128 | 2 | 17% |
| openai | quad | 1024 | 9 | 75% |
| sentence | gt | 128 | 7 | 58% |
| sentence | gt | 1024 | 7 | 58% |
| sentence | quad | 128 | 5 | 42% |
| sentence | quad | 1024 | 8 | 67% |
Q1からの続きです。これを見て明らかなのが、量子化に使う量が128のときは差がないが、量が1024に増えたときはalpacaが有利になるという点です。
つまり、質の良いデータは量子化の性能をスケールさせられることができる(数を多く入れたときにさらに良くさせられる)というのがわかります。ただ、128のときはほぼ差がないというのは興味深い点でした。
仮説Q3:AutoGPTQは量子化条件によっては、BitsAndBytesより常に良くなることがあるはずだ
仮説検証
- AutoGPTQのalpacaで1024のように、強い条件でやったらBitsAndBytesを上回るんじゃない?という点
- 速度の点ではAutoGPTQのほうが速いので、性能も上回ったら嬉しい
| metrics | quant_data | quant_size | win | win_rate |
|---|---|---|---|---|
| flant5 | alpaca | 128 | 4 | 33% |
| flant5 | alpaca | 1024 | 8 | 67% |
| flant5 | dolly | 128 | 5 | 42% |
| flant5 | dolly | 1024 | 3 | 25% |
| openai | alpaca | 128 | 4 | 33% |
| openai | alpaca | 1024 | 6 | 50% |
| openai | dolly | 128 | 7 | 58% |
| openai | dolly | 1024 | 8 | 67% |
| sentence | alpaca | 128 | 6 | 50% |
| sentence | alpaca | 1024 | 5 | 42% |
| sentence | dolly | 128 | 6 | 50% |
| sentence | dolly | 1024 | 3 | 25% |
結果は、評価指標で見たときにalpaca/1024が67%-50%-42%と若干優勢かなぐらいです。
生の値
次に、alpaca/1024に絞って生の値を見てみたいと思います。
| dataset | model | distance | autogptq | bnb | gain |
|---|---|---|---|---|---|
| image_paragraph | minigpt4_llama2_eval | flant5 | 23.36 | 23.82 | 0.46 |
| image_paragraph | minigpt4_vicuna_13b_eval | flant5 | 30.46 | 29.93 | -0.52 |
| image_paragraph | minigpt4_vicuna_7b_eval | flant5 | 27.49 | 28.47 | 0.98 |
| llava_bench | minigpt4_llama2_eval | flant5 | 18.79 | 19.75 | 0.96 |
| llava_bench | minigpt4_vicuna_13b_eval | flant5 | 19.46 | 18.24 | -1.22 |
| llava_bench | minigpt4_vicuna_7b_eval | flant5 | 22.78 | 21.46 | -1.32 |
| science_qa | minigpt4_llama2_eval | flant5 | 23.58 | 23.85 | 0.27 |
| science_qa | minigpt4_vicuna_13b_eval | flant5 | 28.57 | 27.91 | -0.66 |
| science_qa | minigpt4_vicuna_7b_eval | flant5 | 30.44 | 31.56 | 1.12 |
| viquae | minigpt4_llama2_eval | flant5 | 23.88 | 23.91 | 0.03 |
| viquae | minigpt4_vicuna_13b_eval | flant5 | 29.54 | 29.80 | 0.27 |
| viquae | minigpt4_vicuna_7b_eval | flant5 | 26.51 | 27.50 | 0.99 |
| image_paragraph | minigpt4_llama2_eval | openai | 13.93 | 13.87 | -0.06 |
| image_paragraph | minigpt4_vicuna_13b_eval | openai | 16.68 | 16.96 | 0.28 |
| image_paragraph | minigpt4_vicuna_7b_eval | openai | 16.08 | 16.10 | 0.02 |
| llava_bench | minigpt4_llama2_eval | openai | 12.42 | 12.96 | 0.54 |
| llava_bench | minigpt4_vicuna_13b_eval | openai | 13.53 | 12.83 | -0.70 |
| llava_bench | minigpt4_vicuna_7b_eval | openai | 14.28 | 13.87 | -0.41 |
| science_qa | minigpt4_llama2_eval | openai | 11.66 | 11.59 | -0.07 |
| science_qa | minigpt4_vicuna_13b_eval | openai | 14.64 | 14.43 | -0.21 |
| science_qa | minigpt4_vicuna_7b_eval | openai | 15.96 | 16.39 | 0.43 |
| viquae | minigpt4_llama2_eval | openai | 14.21 | 13.99 | -0.22 |
| viquae | minigpt4_vicuna_13b_eval | openai | 16.28 | 16.76 | 0.48 |
| viquae | minigpt4_vicuna_7b_eval | openai | 15.38 | 15.69 | 0.32 |
| image_paragraph | minigpt4_llama2_eval | sentence | 16.34 | 16.51 | 0.17 |
| image_paragraph | minigpt4_vicuna_13b_eval | sentence | 21.75 | 21.68 | -0.08 |
| image_paragraph | minigpt4_vicuna_7b_eval | sentence | 18.88 | 18.87 | -0.01 |
| llava_bench | minigpt4_llama2_eval | sentence | 12.37 | 12.74 | 0.36 |
| llava_bench | minigpt4_vicuna_13b_eval | sentence | 13.76 | 13.45 | -0.31 |
| llava_bench | minigpt4_vicuna_7b_eval | sentence | 15.88 | 14.35 | -1.53 |
| science_qa | minigpt4_llama2_eval | sentence | 15.22 | 14.89 | -0.32 |
| science_qa | minigpt4_vicuna_13b_eval | sentence | 19.17 | 18.80 | -0.37 |
| science_qa | minigpt4_vicuna_7b_eval | sentence | 20.68 | 21.11 | 0.43 |
| viquae | minigpt4_llama2_eval | sentence | 16.27 | 16.26 | -0.01 |
| viquae | minigpt4_vicuna_13b_eval | sentence | 21.08 | 21.16 | 0.08 |
| viquae | minigpt4_vicuna_7b_eval | sentence | 18.21 | 18.57 | 0.35 |
gainは「bnb-autogpq」です。この値がプラスなら、autogptq有利です(距離なので元の値が低いほうが有利なことに注意してください)。
平均値は、トータルが0.52。flant5が1.35、openaiが0.41、sentenceが-1.23でした。全体で見ればやや良いものの、評価指標によっては悪くなることもあります。
評価指標は「絶対的にこれが良い」というのがないというのが難しい点です。
また、一貫してLLaMA2の優位性が示されているのが面白い点です。VicunaよりもLLaMA2のほうが良いというのは直感的にわかるので、これがある程度定量的に示せるのは旨味があります。
評価指標単位のプロット
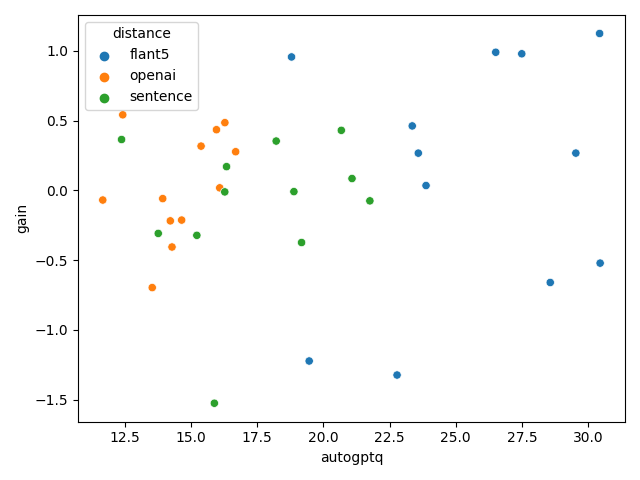
distance単位のプロットです。これはなんともいえないですよね
推論データセット別のプロット
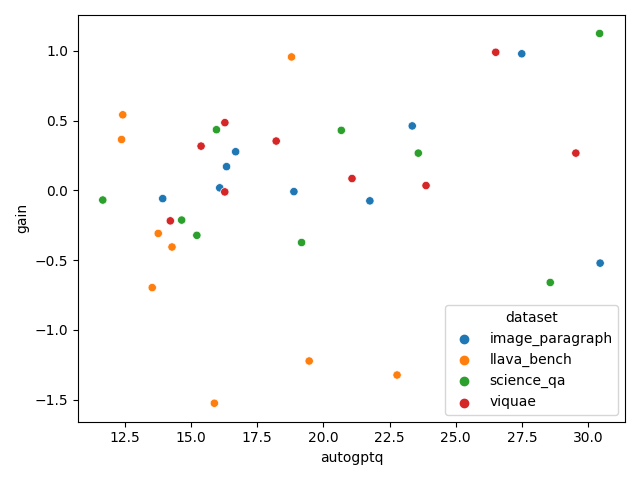
ややデータセット単位で得意不得意あるのではないかなと思います。元のタスクやドメインが豊富なデータを量子化データセットに入れてあげるとAutoGPTQは良くなるのではないかと思います。
量子化データセットをalpaca/1024→dolly/1024に変える
量子化のデータセットをalpacaからdolly(室の悪いデータセット)に変えた場合はどうでしょうか。量子化のサンプル数は同じ1024のままです。
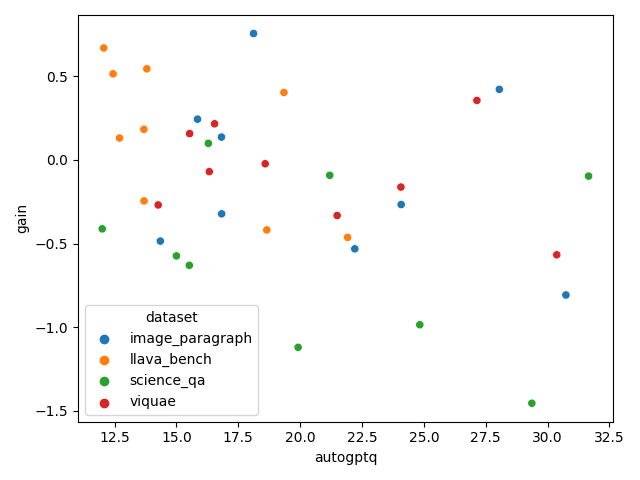
結果は面白くて、ほとんどがGainマイナスになりました。つまり、質の悪いデータセットで量子化したAutoGPTQはBitsAndBytesより悪くなるということです。
結論
長いポストになってしまいましたが、以下のことがわかりました。
- 評価指標について
- LLMの量子化を計測する際の評価指標は、Embeddingの距離で良い
- 距離関数はL1ロスやコサイン距離が考えられるが、サンプル単位のL1ロスでいい。量子化同士の比較、Ground Truthとの比較の両方で使える
- Embeddingのバックボーンのモデルは絶対的に良いのはないが、FlanT5、OpenAI Embedding、Universal sentence encoderどれを使っても出た。ただそれぞれに癖があるので、複数組み合わせるのが良さそう
- GPTのゼロショットの評価は、正確性と創作性のトレードオフを見たいときは便利な可能性があるが、量子化の評価を見たいときは別にこれを使わなくても良い。
- 量子化について
- AutoGPTQで量子化するなら、良質なデータセットを使うと、性能がスケールする。つまり、量子化に使うサンプル数を増やしたときに、量子化性能が良くなる。
- ここで使うデータセットは、普通のLLMのInstruction Tuningのデータセットで良い(VLMのデータでなくても、BitsAndBytesと同程度の性能は出せた)。VLMのInstruction Tuningのデータセットでなくて良い
- AutoGPTQは、良質なデータセットを量子化時に多く食わせるとBitsAndBytesよりも性能的に良くなる可能性があるが、ここの条件を誤ると逆に悪化することも多い。
- 良質なデータセットとは、例えばalpaca_data_cleanedのようなものである。以下の条件が量子化時の良質なデータセットの良い条件ではないか
- 文章そのものがノイジーではない
- 記述されているInstructionが広範囲な内容である
- 記述されているドメインが広範囲な内容である
- その他
- LLaMA2の強さや、データセット間の得意不得意が定量的に示せた
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー