
Qiita開始1年で2000(訂正:3000)Contribution達成してわかったこと


12/21にQiitaが2000Contribution(いいね)を達成しました。正直Qiita始めたときはここまで行くとは思っていなかったので、素直に驚いているとともに、まずは応援してくださった方にありがとう言いたいです。
目次
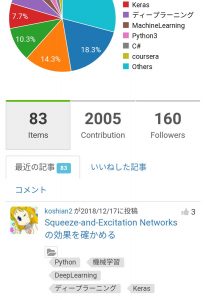
11ヶ月で2000いいね
アカウント登録と初投稿が1/18だったので、11ヶ月ちょいで2000Contributionを達成できました。
一番最初の投稿は仮想通貨のレート取得プログラムでした。
C#で仮想通貨取引所のリアルタイムレートを記録するプログラムを作ってみた
https://qiita.com/koshian2/items/872e2ee601be2bce7b9c
始めたときは、「2年ぐらいで1000ぐらいいければいいかなー」ぐらいの感じだったので、1年でその倍(正味4倍)行けたというのが感慨深いです。機械学習やディープラーニングなどジャンルの注目度が高かったということもありますが、自分で言うのもなんですが、1年で2000はそう簡単にできることではない(年度別ランキングを集計しているサイトによると、せいぜい40人前後らしいです)のでそこは素直に誇っていきたいと思います。
12/26の段階で、「84記事-2032いいね」だったので、今年の終わりには多分2040~2050ぐらいで終わるのではないかなと思います。
さて、自慢話ばかりしてはアレなので、実際1年書いてきてわかったことや気をつけたことを書いていきたいと思います。
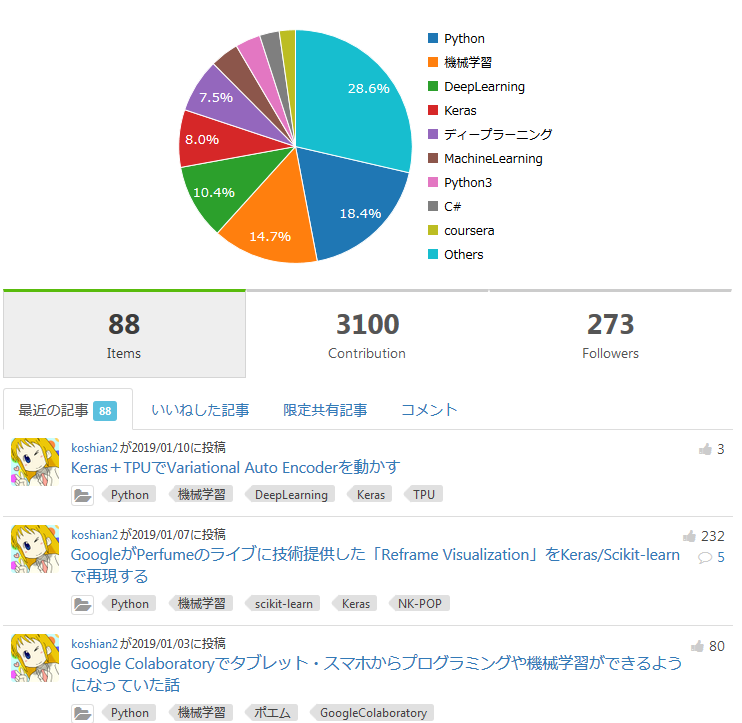
訂正:1/12更新
「1年で2000いいね」とお伝えしましたが、これは正しくありません。登録が2018/1/18、2019/1/12時点で3100いいねだったので、「1年で3000いいね」が正しい情報となります。
「アウトプット=正義」は本当
これだけは伝えたいです。アウトプットを書くことと学習が加速することは必ず比例します。なぜなら、アウトプットを書く段階に意味があるからです。
例えばバグに遭遇したとしましょう。そのバグを解決したいとします。記事を書くのに必要なのはどのような要素でしょうか。
- そのバグとはどういうものなのか
- そのバグはなぜ起きるのか
- 簡単な例でそのバグを再現できるか
- そのバグの解決法とは何なのか
- なぜその解決法が成立するのか
- 仮にシチュエーションを少し変えてやると、それは再現するのか、挙動は変わるのか
正直ここまで書く必要はありませんが、最低でも「バグはどういうものなのか」「解決法はあるのか、ないのか」ぐらいは書いておきたいですね。
実はこれらの論点がはっきりした段階、つまりこれらの整理している段階で、その問題に対する理解の7,8割はできているからです。つまり、記事そのものも意味あるんだけど、同時に記事を書くのに論点を落とし込んでいることがまず意味があるのです。
なら、記事を書かずに脳内で整理すればいいのかという疑問もありますが、自分は余裕があれば記事を書いたほうがいいと思います。なぜなら、自分が書いた記事はバックグラウンドが自分と100%相関する唯一の存在なので、将来的に欲しい情報というのは、過去の自分の記事の中にあるということがでてきやすくなります。
ある時点でわからなかったことは、将来的に「これどうだっけ?」ってわからなくなることも多いので、Google検索するにしても自分が書いた記事が引っかかることがよく出てきます。そもそも、わからないたびにGoogle検索して10ページぐらい探すのなら、自分の記事1ページで完結してしまうのが楽ですよね。
それに、完成度の差はおいておいて、記事を完成させてしまえば自分の中で「この問題は一定の解決済みだ次に移ろう」と区切りをつけることができるのです。そういう意味でも、必ずしもブログ記事でなくても良いですが、何らかのアウトプットをするというのは意味があると思います。
別にアウトプットはQiitaだけではない
実際自分がこちらのWordPressに書いている通り、アウトプットはQiitaだけではないです。むしろ、Qiitaだけにアウトプットするとモチベを維持する点から良くないというケースがあると思います。
例えば、先程出した「バグの解決法」なんかは検索流入はあっても、いいねがつくことはあまりないような気がします。Qiitaの場合、PVの増加という物理的な動機づけよりも、「いいねによって承認欲求を満たす」という漠然的な物が大きなモチベとなります。いくらいい記事でもいいねがつきにくような内容は、モチベ的に維持するのがきついのではないかなと思います。これはあくまで自分の意見なので、別の意見があっても良いと思います。
逆に言えば、「バグの解決法」は一定の検索流入はあるので、いいねはつきにくいものの、SEO的にはかなり美味しい内容ではあるのです。そういった内容は、WordPressやはてなブログ(はてなは独自ドメイン使えます)でも良いのではないでしょうか。むしろそっちのほうがモチベを維持できるかもしれません。
記事を書くというのは、始めはかなりの負担になるので、何よりも自分のモチベを維持することを第一に考えると続きやすいのではないでしょうか。
セッション継続時間が低いからって記事の質を落とさない
QiitaにはGoogle Analyticsをつけられますが、これで「セッション継続時間」というのが見れます。これを見ると驚くのですが、セッション継続時間が結構低い(せいぜい1分~1分半程度)なのです。書いている側としては結構「あーせっかく書いても読んでくれないんだな」って落ち込むこともあります。
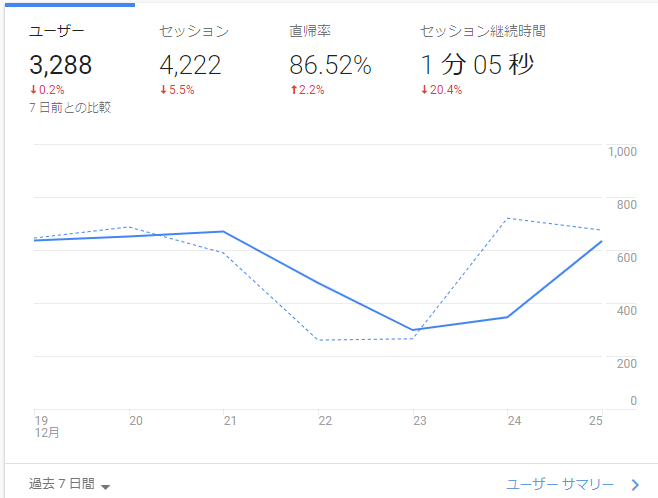
しかし、これはよく考えると平均の罠です。期間は若干変わりますが、参照元別に見ると意外なことがわかります。
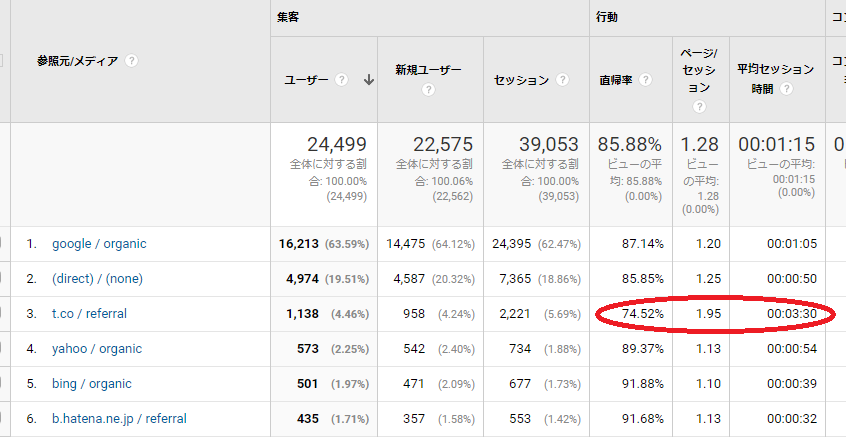
t.coつまり、この場合はTwitterからの参照だけ異様にセッション継続時間が長いですよね?つまり、参照元が異なれば長めの記事でもちゃんと読んでくれるのです。もちろんわかりやすい記事を書く必要はありますが(それは他人のためではなくて、他人にわかりやすく説明できるレベルまで理解できればそれはマスターしたも同然だからです)、「セッション継続時間が低いから記事の質を落としても良い」にはならないと自分は思います。
セッション継続時間の分布が2コブになっているのはよく考えるとわかります。なぜなら、自分が答えを欲してGoogle検索しているときに、答えだけわかればOKということも多いですよね。なので、「読みたくない」のではなくて「Google検索で調べているときは答えだけ知りたいから、読んでいる側はいくら良い記事であっても取捨選択している。その結果、検索流入ではセッション継続時間が低くなる」と考えるほうが自然だと思います。
なので、Twitter経由にしろ何にしろ、ちゃんと時間をかけて読んでくれる人がいるのなら、内容を落とさないほうが良いのではないかなというのが自分の考えです。もちろんそこはケースバイケースなので、さっくり答えだけ知りたい人に最適化するか、じっくり読みたい人に最適化するかは分かれるでしょう。しかし、セッション継続時間が低い→読んでくれないのでは?→質を落とすというのはミスリードではないかな、と自分は思います。
だいぶアバウトになってしまいましたが、皆さんのヒントになったら幸いです。重ね重ねになりますが、2000Contribution達成できたのは読者の皆様のおかげなので、この場を借りてお礼申し上げたいと思います。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー