
論文まとめ:UniVTG: Towards Unified Video-Language Temporal Grounding
Posted On 2023-08-24


- タイトル:UniVTG: Towards Unified Video-Language Temporal Grounding
- 著者:Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, Mike Zheng Shou
- 論文URL:https://arxiv.org/abs/2307.16715
- コード:https://github.com/showlab/UniVTG
- デモ:https://huggingface.co/spaces/KevinQHLin/UniVTG
- カンファ:ICCV 2023
目次
ざっくりいうと
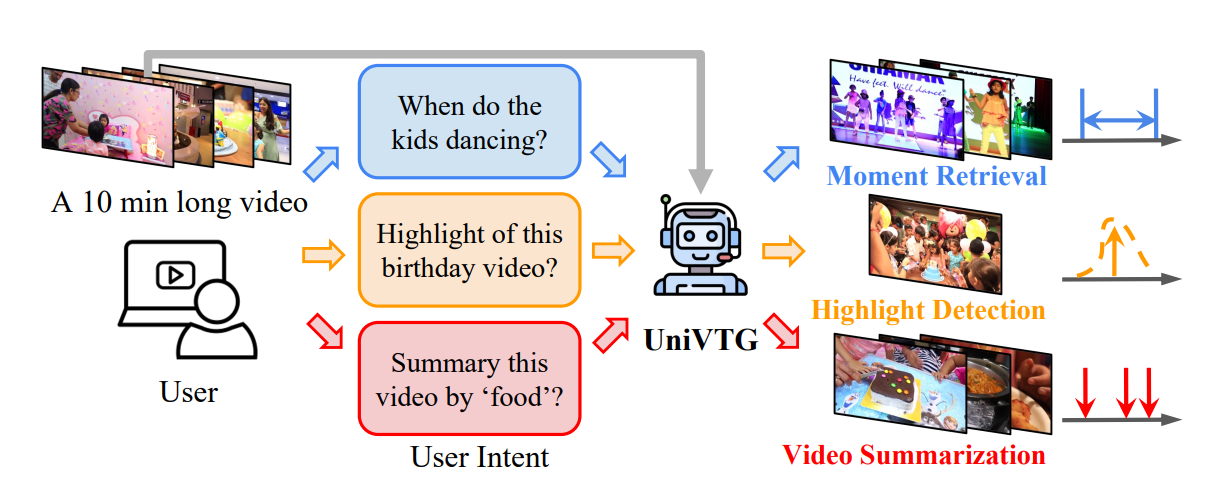
- モーメント検索、ハイライト検知、動画要約をプロンプトベースで1つのモデルで実行できる基盤モデル
- 疑似ラベルの生成に工夫点が多い。モデル構造は時系列方向の物体検出
- CLIPやVideoCCのような事前学習モデルを時系列方向に拡張しつつ、タスクを統合したのが新規性
背景の理解
UniVTGの前にも、Temporal Action Detectionのように時間方向に検出を走らせるタスクはあった。

- Object Detection(物体検出):空間方向に検出を走らせる
- Temporal Detection:時間軸方向に検出を走らせる
今回のタスクは時間軸方向になにか検出を走らせるタスク
導入
- タスク
- モーメント検索
- プロンプトに対する連続した時間窓(時間あたりの区間)の検索
- ハイライト検知
- 最も価値のあるピンポイントを検出
- 動画要約
- 動画を要約するための不連続なショットの収集
- モーメント検索
- これらの3タスクを動画の時間的根拠に基づく事前学習を初めて行ったもの
- 背景
- GLIP(画像に対するゼロショット物体検出やキャプション生成)に見られるように、空間方向のGroundingは出ている
- Image-Languageの事前学習は進歩しているが、Video-Languageの事前学習はそれほど進歩していない
- 現在のVideo-Languageは、動画検索のように動画単位の方向に設計されている
- この理由
- 時間軸方向のGroundingが進まない理由:アノテーションコストが高い
- UniVTGの設計
- タスクの側面から、動画を細かいシーケンスに分解
- 各タスクに対してクエリ条件を定式化
- 時間軸方向のラベルのたりなさはCLIPベースの擬似ラベルを使用
- モダリティ融合とモダリティアラインメントのためのシングルストリームとデュアルストリームの経路を考案し、主要な3要素を解読するためのヘッドを作成。各タスクに対応
手法
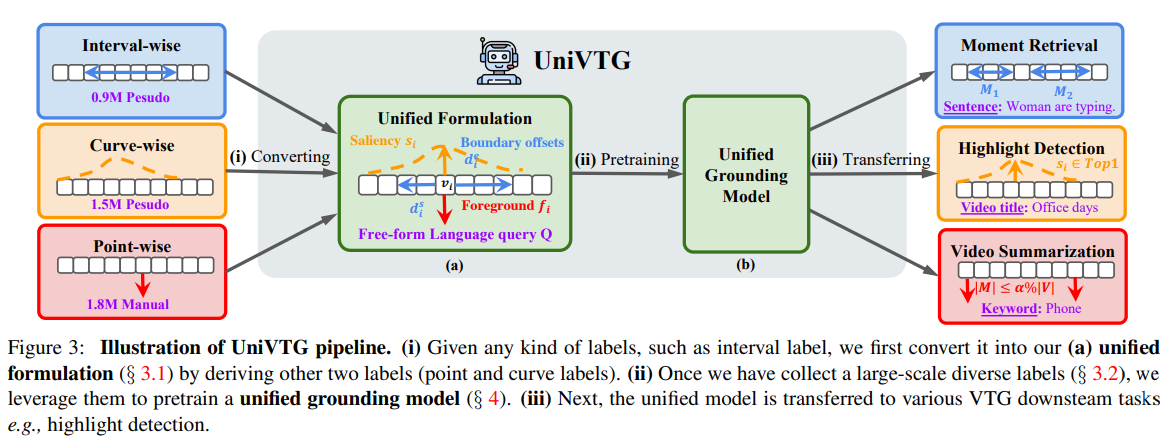
Unified Formation
長い動画をいくつかのクリップに区切り、クリップ単位で評価
- Foreground Indicator
- Point-wiseに対応。特定のクリップなら1, それ以外なら0
- Boundery Offset
- Interval-wiseに対応。特定の区間なら1, それ以外なら0
- Saliency score
- Curve-wiseに対応。クエリとの関係性を連続量で表す
ラベリングをどうする?
- モーメント検索
- 動作の区間推定
- ASR(Not音声解析)を使うと、開始と終了のタイムスタンプを得られる。しかしノイジー
- VideoCCは動画の事前学習だが、時間的根拠を利用できる可能性がある
- 区間が得られたら、その部分のクリップを1、それ以外を0とする
- ハイライト検知
- 曲線のラベリングを人間がやるとアノテーションが高価
- CLIPによるスコアリングを使い、動画のクリップ単位のCLIP類似度を計算
- しきい値処理によって疑似ラベルを作る
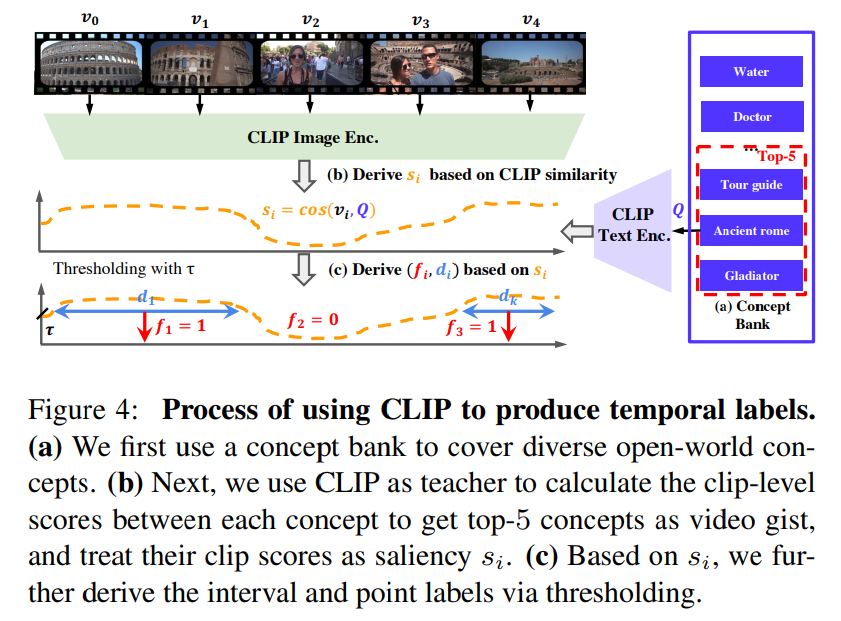
- 動画要約
- 動画全体に対して特定の割合(例:2%)のクリップ集合を作る
- Ego4Dデータセットが時間軸方面の点単位のラベリングを行っているためそれを活用
- “I am opening the washingmachine” at ti = 2.30 sec
モデル構造
- Moment-DETRと整合性を保つ
- DETRは物体検出。物体検出は空間方向だが、これを時系列方向に変えたもの
- 動画とテキストのエンコーダーはCLIP(ViT-B/32)とSlowFast(R-50)
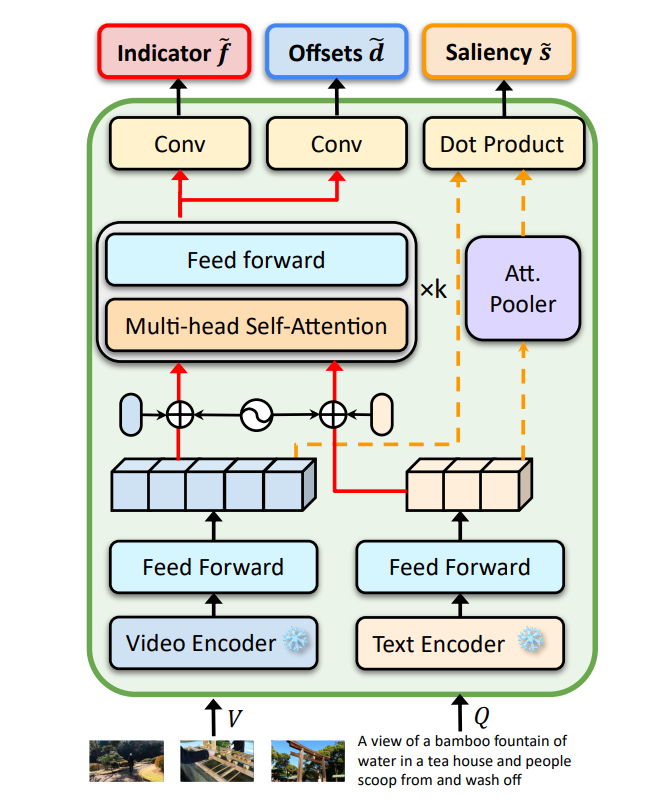
- Indicator f, Offset d, Saliency sごとに損失を計算し、損失関数を適用
- 物体検出を時系列でやってるイメージ
- 推論時は、時系列方向にNMSを適用
結果
定量評価
モーメント検知(PTは事前学習のあとにFine tuning、ZSはゼロショット)
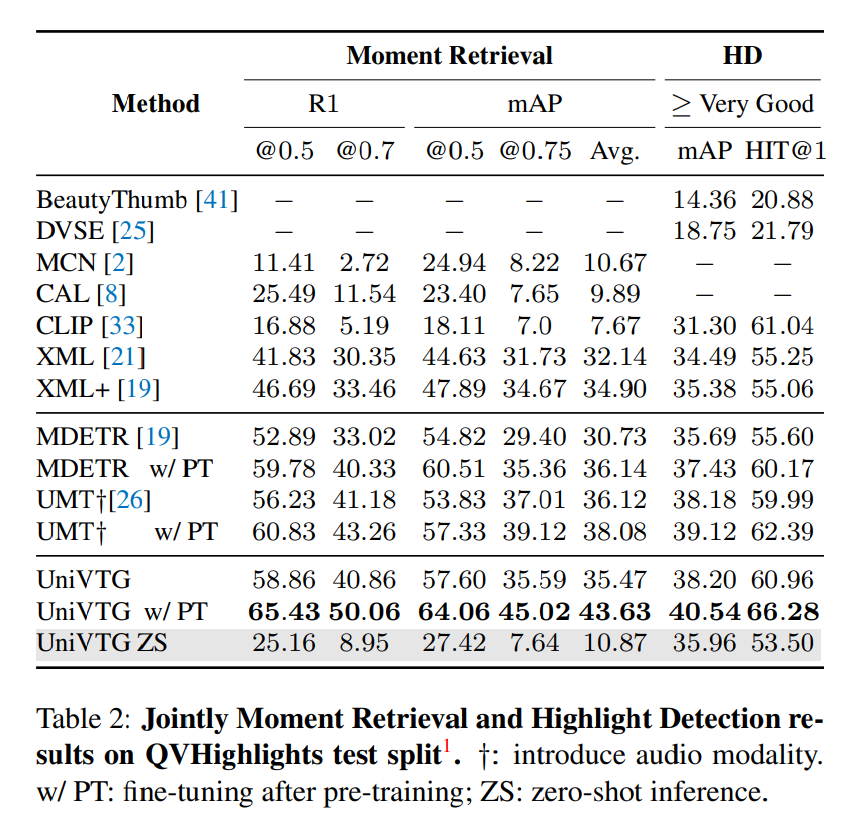
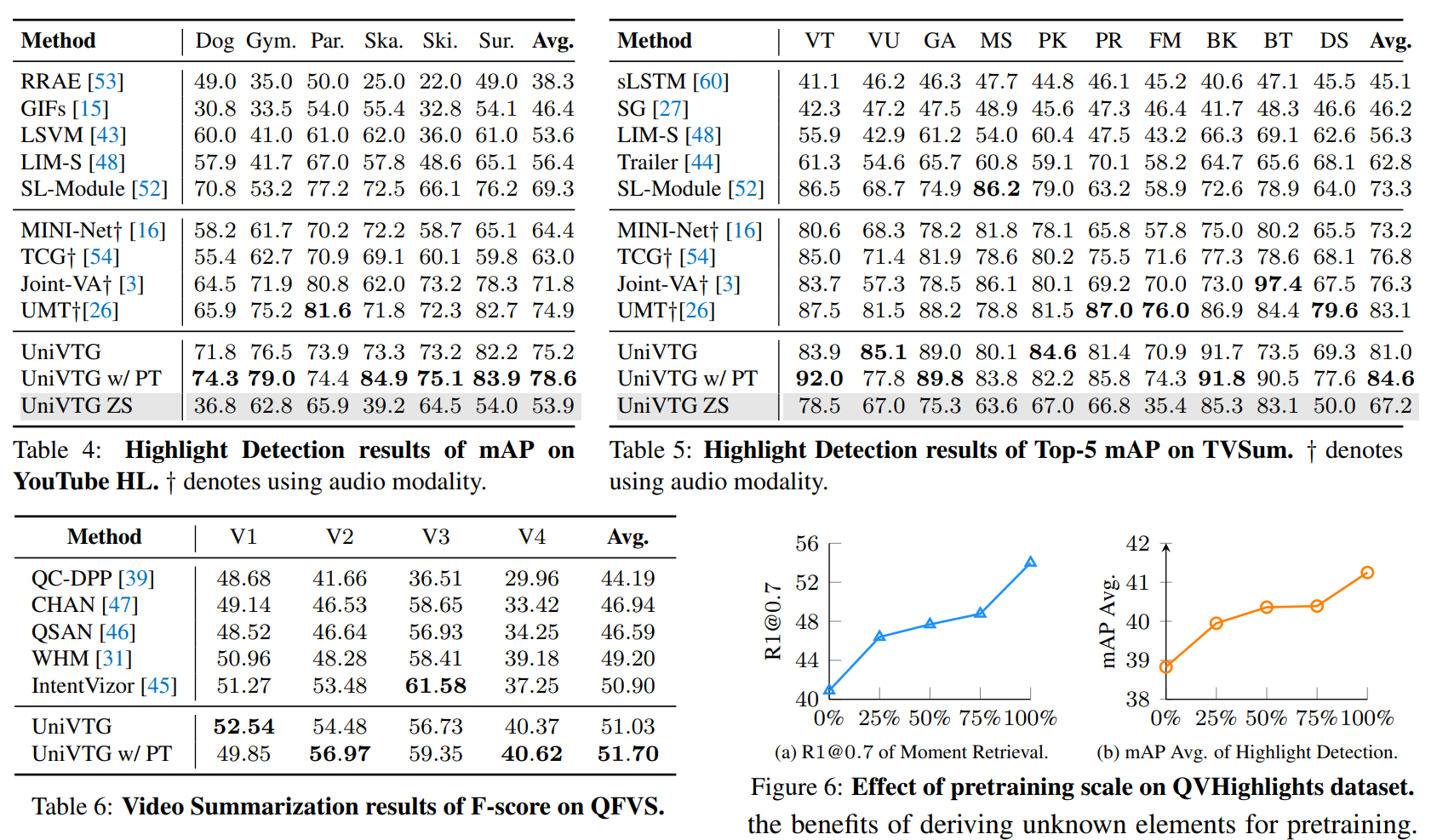
ハイライト検知。Top5まで含めればゼロショットでもある程度行けそう
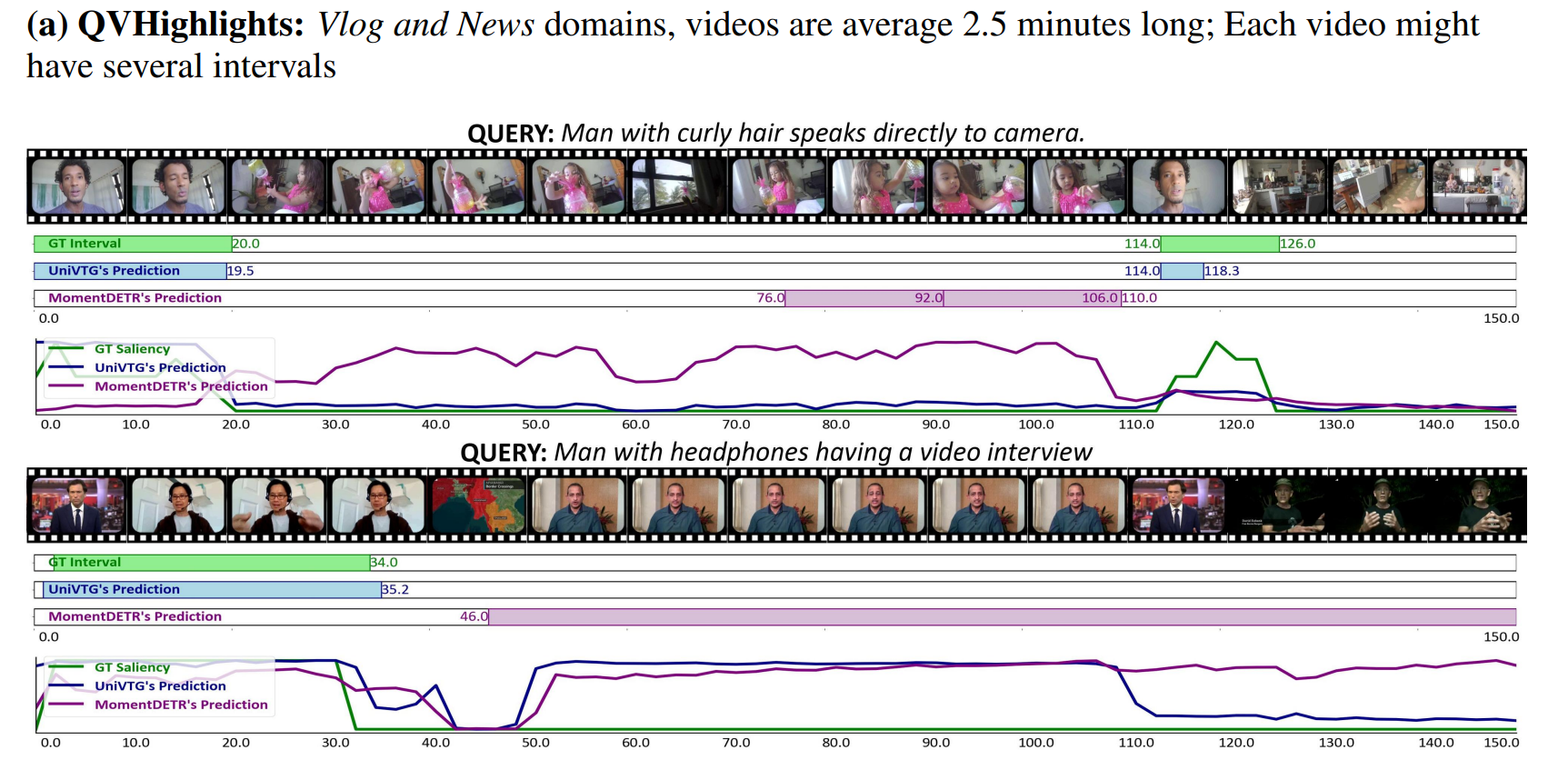
定性評価

所感
- めっちゃ実用的なので精度はともかく(GitHubでSoTA表示出てるのすごい)とりあえず使ってみたい
- 作者の方ライセンスをMITにしてくれてありがとう。論文引用したい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー