
論文まとめ:Zero-shot Image-to-Image Translation
Posted On 2023-02-16


- タイトル:Zero-shot Image-to-Image Translation
- 著者:Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, Jun-Yan Zhu(カーネギーメロン大学、Adobe)
- 論文:https://arxiv.org/abs/2302.03027
- プロジェクトページ:https://pix2pixzero.github.io/
- コード:https://github.com/pix2pixzero/pix2pix-zero
目次
ざっくりいうと
- 訓練済み拡散モデルを用いて、画像変換タスクを、追加学習なし・手動プロンプトなしで行う研究
- GPT-3の生成文章で、ドメイン間のCLIP埋込量の差を求め、画像の編集方向とする
- クロスアテンションガイドで、変換後での画像構造の維持をサポート
- GANによる蒸留で推論を3800倍高速化

導入
- Stable Diffusionなどの拡散モデルは強力だが、実画像の編集に再利用することは、依然として困難
- 画像は「thousand words」と言われるように、質感や光の加減、形状の微妙な違いなどを言語化できないものが多い。プロンプトの指定は面倒で時間かかる
- プロンプトで指定したとしても(例:cat→dogの変換)、変更したい内容を指定するだけで、残したい内容は指定できない
- 学習不要、プロンプト不要の既存の拡散モデルに基づく画像間変換アプローチ:pix2pix-zero
- ユーザは入力画像に対して、手動でテキストプロンプトを作成することない。ソース→ターゲットドメイン(例:猫→犬)と編集方向を指定するだけ
- 編集方向・画像ごとに追加学習を行う必要がない。事前に学習したStable Diffusionを直接利用可能
- pix2pix-zeroの新規性
- CLIPとGPT-3を用いた、画像の編集方向を自動に発見する機構
- クロスアテンションガイドによる元画像の構造維持
- pix2pix-zeroでやりたいことは、編集後の画像を表現するためのStable Diffusion内の潜在乱数の最適化
- GAN-inversionと発想は近いが、編集タスク込みで最適化
- 拡散モデルは原理的に反転可能だが、反転された乱数をそのまま用いると悪影響があるため、自己相関による正規化を追加
- 高速な推論のため、拡散モデルからConditional GANを蒸留し、推論時間を3800倍高速化
- GANがダウンストリームタスク扱いされている
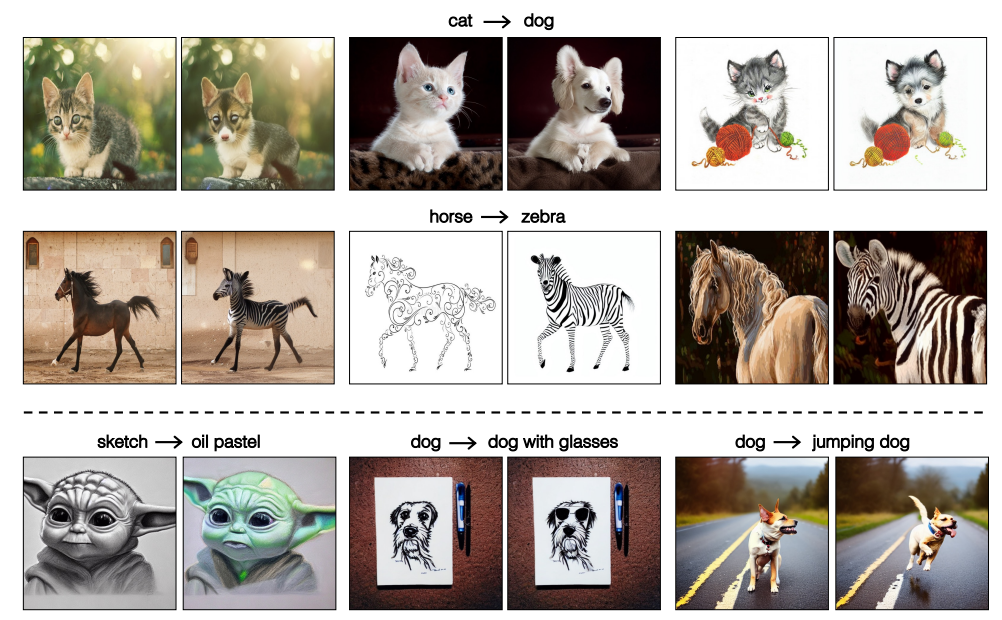
関連研究
- 画像間編集やGANの潜在空間への投影は古くからある
- 近年大規模なText-to-Imageモデルが出ているが、プロンプト以外の生成過程の制御が限定的
- SDEditは、ユーザーの編集ガイドとともに、入力画像にノイズを加えて編集し、ノイズを除去して高品質化
- GLIDEやStable Diffusionでは、編集する場所を限定するために追加のマスクを使う
- PaletteやInstructPix2Pixは、画像間変換に合わせた画像間変換タスクに合わせた条件付き拡散モデルを学習する
- Imagicやprompt-to-promptは構造を保持した編集が可能
- 特にImagicは編集結果が素晴らしいが、各画像に対してFine-tuningする必要がある
- prompt-to-promptはFine-tuningが不要。クロスアテンションマップを用いて構造を保持
- 本研究とprompt-to-promptとの違い
- 本研究は、入力画像に対するテキストプロンプトが不要(prompt-to-promptではいる)
- 編集されたテキストとマッチしない可能性のあるクロスアテンションマップを直接利用しないため、よりロバスト
- 本手法は実画像に適した手法でありながら、合成画像に対しても有効
- 本研究のベースラインや、SDEditやprompt-to-prompt
手法
問題:「編集後の画像をStable Diffusionのノイズ空間で表現するにはどうすればいいですか?」
- 入力画像を拡散モデルのinversionを使って、潜在ノイズx_invを計算
- ただ、反転されたノイズを直接利用するのは良くないので正則化をする
- (これとは別に)BLIPを使って入力画像のキャプションを作る
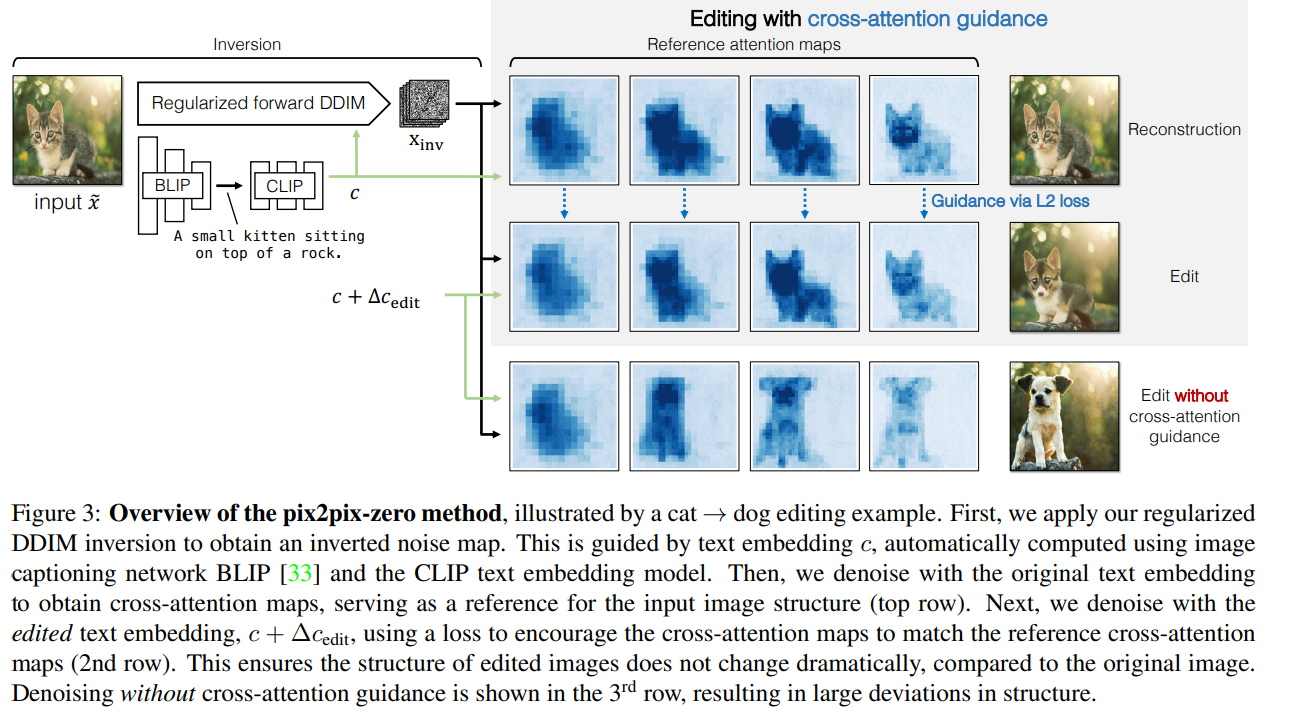
ノイズの正則化
- DDIMのinversionで生成されるノイズマップは、ガウスノイズの統計的性質に従わないことが多く、編集性能に悪影響がある
- 本来のガウスノイズ
- 任意のランダムな位置にのペア間が無相関
- 各空間位置の平均が0、分散が1であるべき
- =自己相関が単位行列になるべき
- 64×64×4のノイズに対して、ノイズマップのピラミッドを作る
- 2×2、4×4、6×6、8×8のAvgPoolをとる(η^0, η^1, …, η^3)
- 空間方向の自己相関をとり、解像度ごとに加重平均をとって、1つのL_pairを作る
- これがガウスノイズの性質を満たしてほしい→正則化項にする
- ノイズ正則化はStyleGAN関連の研究から
- ノイズ正則化項だけだと発散してしまうので、VAEのKLロスを追加
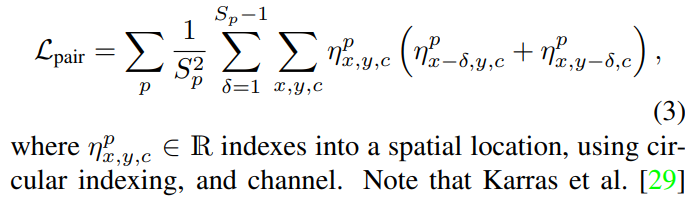
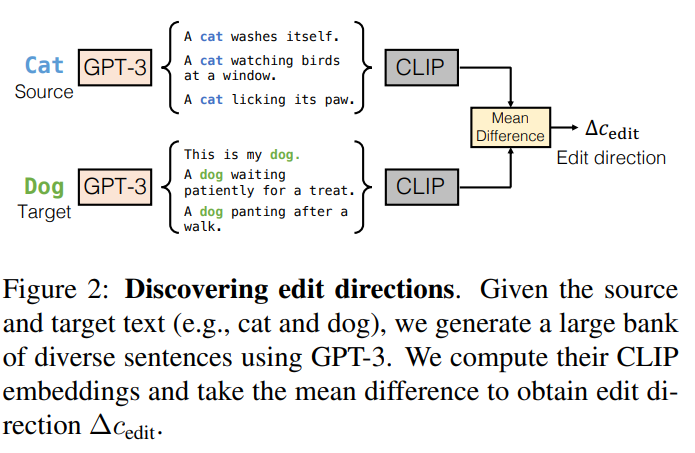
編集方向を見つける
- GPT-3でソース・ターゲット文生成して、CLIPのText Embeddingをとり、ソースターゲット間の差⊿c_editを計算
- GPT-3がData Augmentation的な効果を果たしている(私見)
- この差分が拡散モデルの生成方向を規定する
- この方法は5秒程度で計算し、一度だけ事前計算すれば良い
クロスアテンションのガイドによる編集
- 最近の大規模拡散モデルでは、ノイズ除去のU-Netでクロスアテンションを使っている
- キーはCLIPのText Encoderの埋め込み量
- prompt-to-promtの研究によると、画像の構造とクロスアテンションマップが密接な関係にあることがわかっている
- M_i,jというクロスアテンションマップがあったとき、iが空間方向で、jがテキストトークン方向の関係がある
- 先程計算した編集方向⊿c_editをKeyに足して、クロスアテンションをかけることで、Embeddingの差分を画像の編集方向に反映できる
- 編集方向だけだと、画像構造が保持されないので、クロスアテンションによるガイドを使って、画像構造を保持


結果


- prompt-to-promptの上位互換
- Structure Differenceという評価指標はこの論文から(ViT)
ConditionalGANによるモデル高速化
- 拡散モデルは多くのステップが必要なため遅い
- 拡散モデルから、入力画像と編集画像のペアを生成し、条件付きGANを学習する
- Co-Mod-GANによる蒸留では、A100で1枚生成するのに0.018秒で3800倍の高速化

所感
- ついにこれが来たかという印象だったが、蓋を開けてみるといろいろな発想が使われていて面白かった。ノイズの正規化はなるほどとなった
- 拡散モデルだが、主としてやっていることは、GAN-inversionの高性能化にかなり近い印象がある。プロンプトの最適化の点からは近いのかも?
- CLIP Embeddingの差から編集方向に変換できるのが、最初自明ではないような気がしたが、クロスアテンションでつなげているのが興味深かった。GPT-3からCLIPにつなげるのが「これめっちゃおもろいやん」となった
- 「拡散モデルは推論重いから、蒸留して下流タスクはGAN使うと速いよ」というのが新しい発見。GANもまだ捨てたものではない
- コードがMITで公開されていて遊べてよい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー