
論文まとめ:EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
Posted On 2023-06-01


- タイトル:EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
- 著者:Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, Yue Cao(BAAIなど)
- カンファ:CVPR 2023 Highlight
- 論文URL:https://arxiv.org/abs/2211.07636
- コード:https://github.com/baaivision/EVA/tree/master/EVA-01
目次
ざっくりいうと
- マスク画像モデリング(MIM)を、重い教師データなしで10億パラメータまでスケールすることを実証した研究
- MIMの予測対象をマスクされたピクセルではなく、CLIPの特徴量にすることで、幾何的・意味的な特徴の両方を学習
- Vision centricな基盤モデルの第一歩で、CLIPを学習と精度の両方から効率化を達成。画像言語の新たな架け橋として期待
関連する話
- EVA CLIP
- Stable Diffusionのプロンプト予想のコンペの2nd solution(PFNチーム)
導入
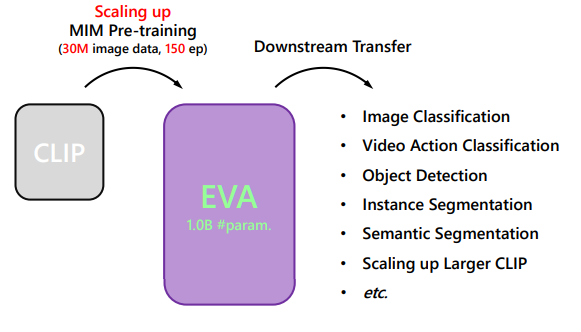
- EVA:「Explore the limits of Visual representation at scAle」
- NLPにおけるマスク言語モデルは、ほぼ無制限のラベルなしデータを使用してTransformerを数十億までスケールアップできた。ゼロショット転移性も持つ
- マスク画像モデリング(MIM)は、画像モデルの事前訓練とスケーリングのための有効なアプローチ
MIMとは
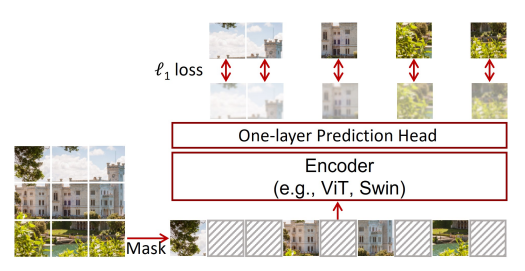
続き
- 動機:vision centricな基盤モデルを作って、数十億パラメーターまでスケールしたい
- 億単位の画像事前学習モデルは、依然として数億のラベル付きデータで教師あり/弱教師あり学習に大きく依存。これらのデータは一般的にアクセスできない
- 純粋なMIMのみでは億単位のサイズのモデルでは性能を出せない
- なぜ?
- 自然画像が生の情報の乏しい
- 低レベルの幾何学と構造情報だけでなく、高レベルのセマンティクスを抽象化する必要があり、これはピクセルレベルの回復タスクではほとんど捉えられない
- これをどう解決した?
- MIMの予測対象をCLIPの画像特徴にする
- なんでこれがうまくいくの? 以下の2点の両方を捉えられるから
- 画像-テキスト対照学習の高度な意味的抽象化
- MIMにおける幾何学と構造の優れた捕捉
- その結果どうなった?
- バニラのViTエンコーダーを10億まで効率的にスケールアップできて、下流タスクにうまく伝達可能な視覚表現を学習できた
- 数千万から数億のラベル付き画像を必要とする他のSoTAの基盤モデルとは異なり、EVAにはコストのかかる教師あり学習段階が不要
- 例:BEiT-3(BERTの画像版)。事前学習用に画像-テキストがペアになった大規模なコーパスが必要
- Vision & Languageの新たな架け橋となる手法として期待できる
- 11億パラメーターのCLIPで画像エンコーダーをEVAで初期化したら、よりサンプルと計算量が少ない条件で、ゼロショット画像/ビデオ分類でゼロから訓練する場合より良い精度になった
- 異なるモダリティ間のギャップを埋める際にMIMが有効であると期待
Fly EVA to the Moon
Feature Instrumentality Project
- マスクされたCLIPの画像特徴量を、画像パッチで条件付して再構成するMIM
- 追加のCLIPのトークナイゼーションは、下流タスクで良い精度を出すためには不要
- 特徴抽出は事前学習が長くなるにつれて、一貫した性能向上が見られない
- マスクされた画像とテキストが一致した視覚特徴を回帰することは、MVPで研究されており、MILANで再検討された。本手法独自のものではない
事前学習用アーキテクチャ
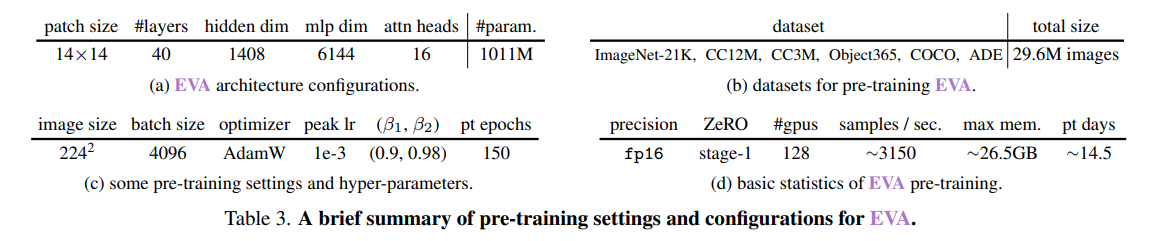
- 普通のバニラViT
- 入力パッチは[MASK]トークンで40%マスキング
- EVAの事前学習に使用したデータを表3bにまとめた。画像-テキスト(CC12M, 3M)のデータは、キャプションのないデータのみ使用
下流タスクでの結果
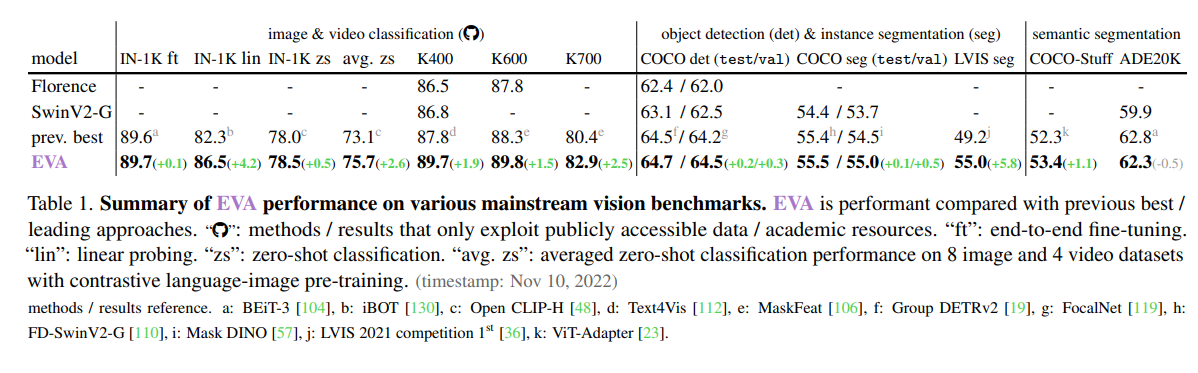
IN1kでLinear-ProbeとFine-tuningの差がもうあまりないのはやばい。Zeroshotの78.5%はResNet-50+CutMixのFine-tuningを超える
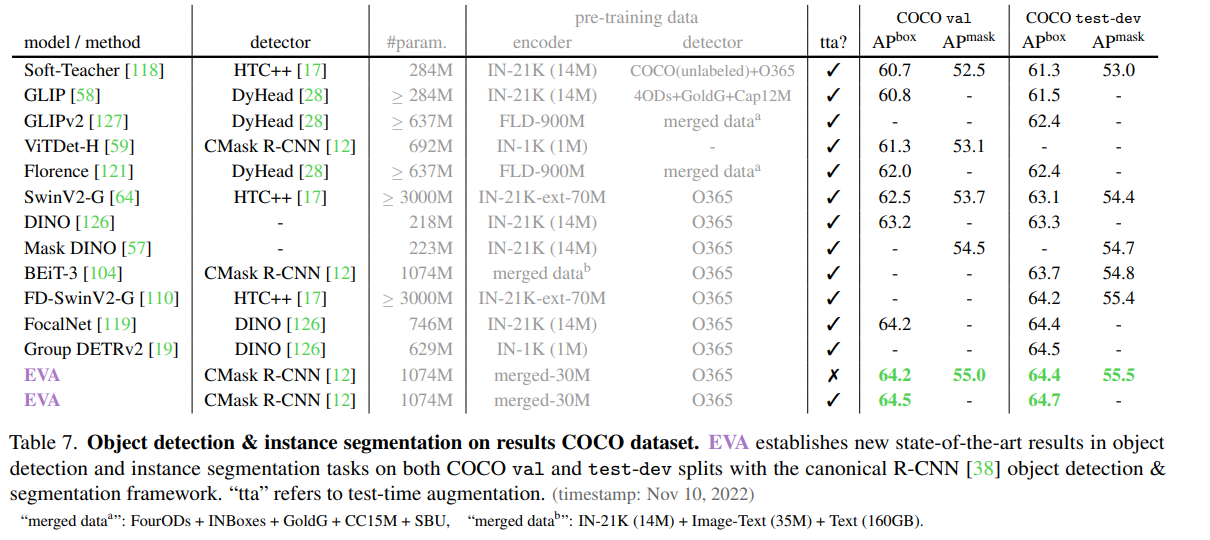
検出系
動画での行動認識
- 空間-時間的な注意を介して単純にビデオデータを処理し、ビデオ関連のタスクのための特定のアーキテクチャの適応はなし
- Kineticsで分類(K-400、K-600、K-700)
- K-722トレーニングセットを用いて、8フレーム、224^2解像度で40エポックのEVAを訓練し、次に各データセットで1、2エポックだけEVAを微調整する
- K-722の中間的なファインチューニングを行わず、画像のみで事前学習したEVAをK-400に直接適応させた場合も、88.4%という非常に競争力のあるトップ1精度
CLIPへの応用
EVAが幅広い視覚下流タスクのための強力なエンコーダであるだけでなく、視覚と言語の間の架け橋となるマルチモーダルピボットである。Vision centricなモデル
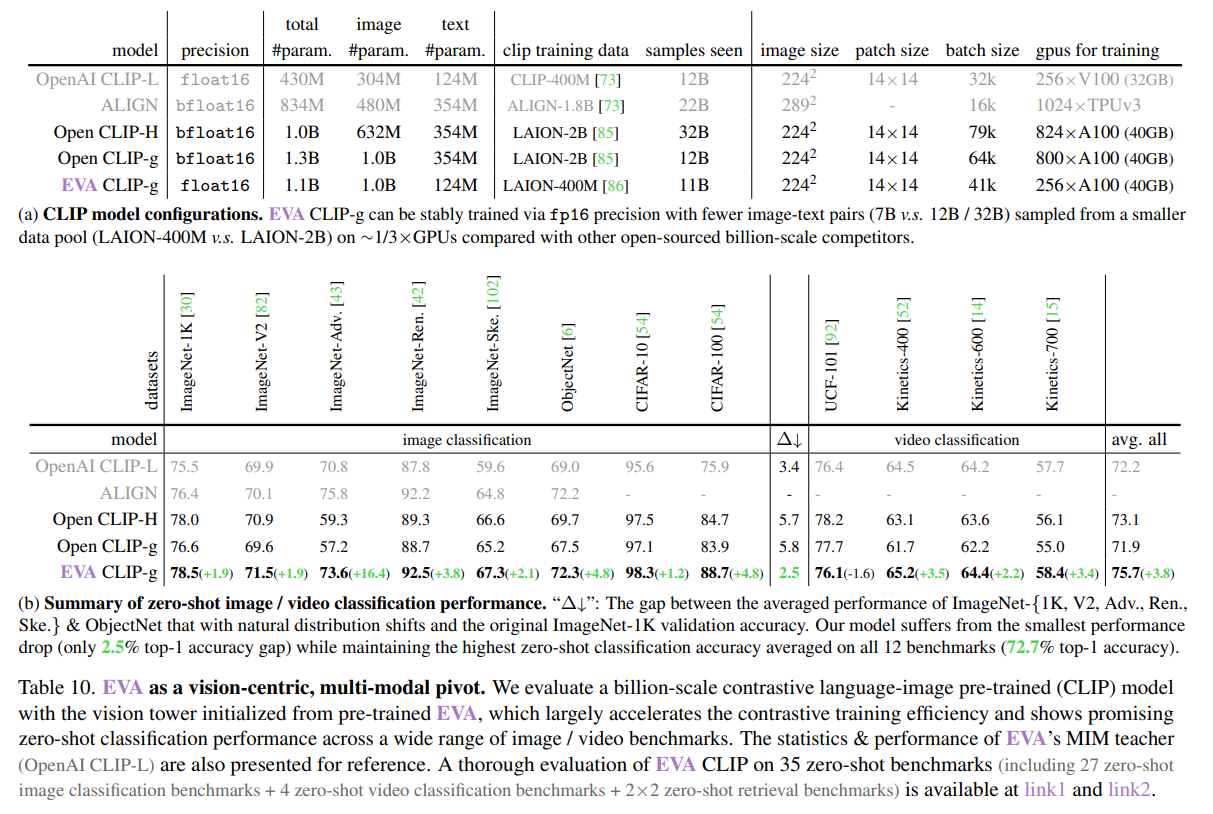
- 設定:画像エンコーダーをEVA、テキストエンコーダーをOpenAI CLIP-Lで初期化
- Open-CLIP-gがLAION-2Bで訓練したのに対し、EVA CLIP-gはLAION-400MでOpen-CLIPより良いゼロショット精度を出せている
- 計算効率化も達成
- OpenCLIPの訓練は、通常深刻な訓練の不安定性に悩まされる。そのためにbfloat16を使わなければならない
- OpenCLIPは学習効率が低く、モデルのスケーリングが下流タスクで支障をきたす可能性がある

Zeroshotもだが、Linear-ProbeとFine-tuningの差がかなり縮まった
結論

Neon Genesis!!
所感
- 画像のMIMがうまくスケールできない理由とその解決法が鮮やか。CLIPのリファイン要素が強いが、Vision centricな基盤モデルを作ろうとしているのが面白い
- モデルが一瞬で公開されていてすごく良い
- CVPR 2023 Highlight通ってるのが強い
- EVAの表記がひたすら初号機色なのにこだわりを感じる(Neon Genesis言いたかった説)
- 2号機(続編)になるとさらにこれをタイトルにつけてくる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー
One Comment