
論文まとめ:Text2Human: Text-Driven Controllable Human Image Generation
Posted On 2022-09-30


* タイトル:Text2Human: Text-Driven Controllable Human Image Generation
* 論文URL:https://arxiv.org/abs/2205.15996
* 著者:Yuming Jiang, Shuai Yang, Haonan Qiu, Wayne Wu, Chen Change Loy, Ziwei Liu
* 所属:南洋理工大学、SenseTime Research
* カンファ:SIGGRAPH 2022
* コード:https://github.com/yumingj/Text2Human
目次
ざっくりいうと
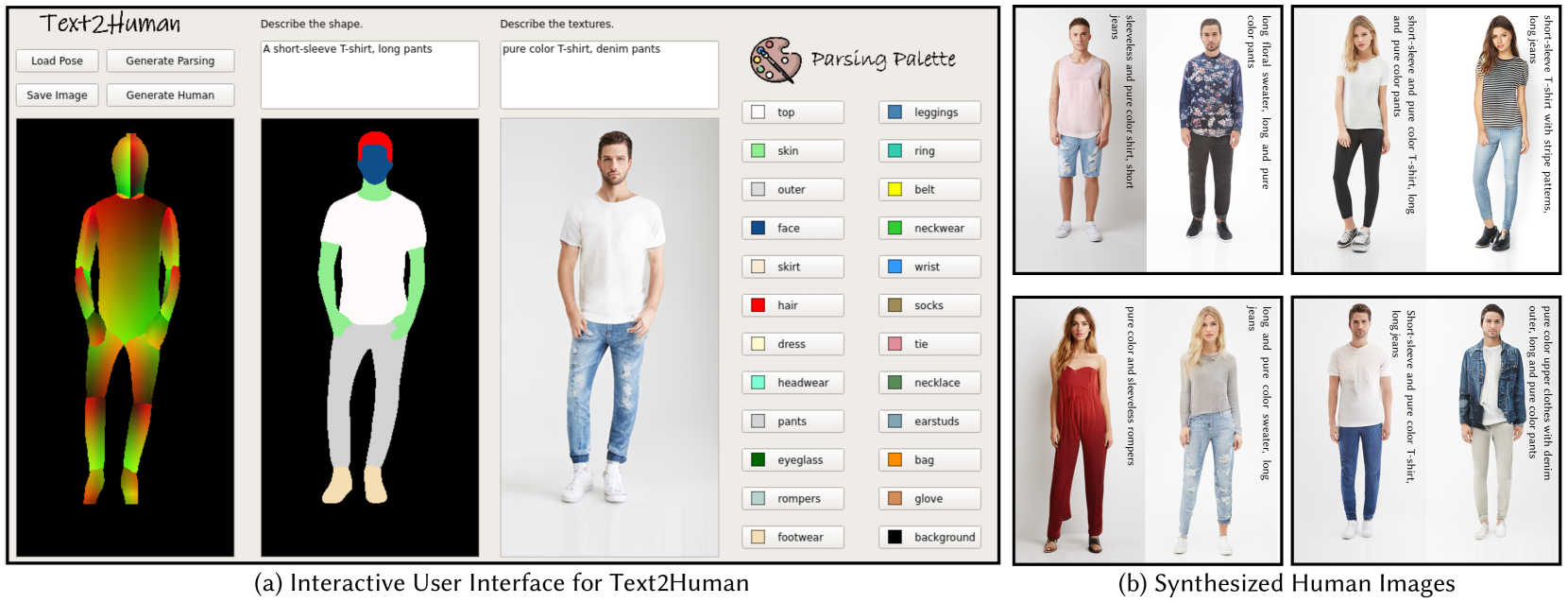
- 人間のポーズマップから、テキストの誘導により、服の形状やテクスチャをユーザーが指定しながら、着用後の画像を生成する研究。
- 2段階のモデルで、(1)服の形状のパーシングマスクを推定、(2)テクスチャを意識しながら着用後の画像を生成する。前者の結果を人間が修正することも可能。
- 後者のモデルにVQVAEベースの拡散モデル+Mixture-of-Expertsのサンプラーを導入することで、先行研究より複雑で多様性のあるテクスチャの服を生成できるようになった。
- この他に「DeepFuision-MultiModal」というデータセットを作り公開した
関連研究
- TryOnGAN (Lewis et al., 2021) がHumanGAN (Sarkar et al., 2021b) が先行研究
- TryOnGANはポーズを条件としたStyleGAN2ネットワークを学習し、与えられたポーズ条件下で人間画像を生成できる
- HumanGANは、VAEに基づく人物画像生成フレームワークを提案
- これらの手法では、人物生成のきめ細かな制御ができない
Text2Human
- 入力
- human pose$P\in\mathbb{R}^{H\times W}$
- texts for clothes shapes $T_{shape}$
- texts for clothes textures $T_{texture}$
- 出力
- human image$I\in\mathbb{R}^{H\times W\times 3}$
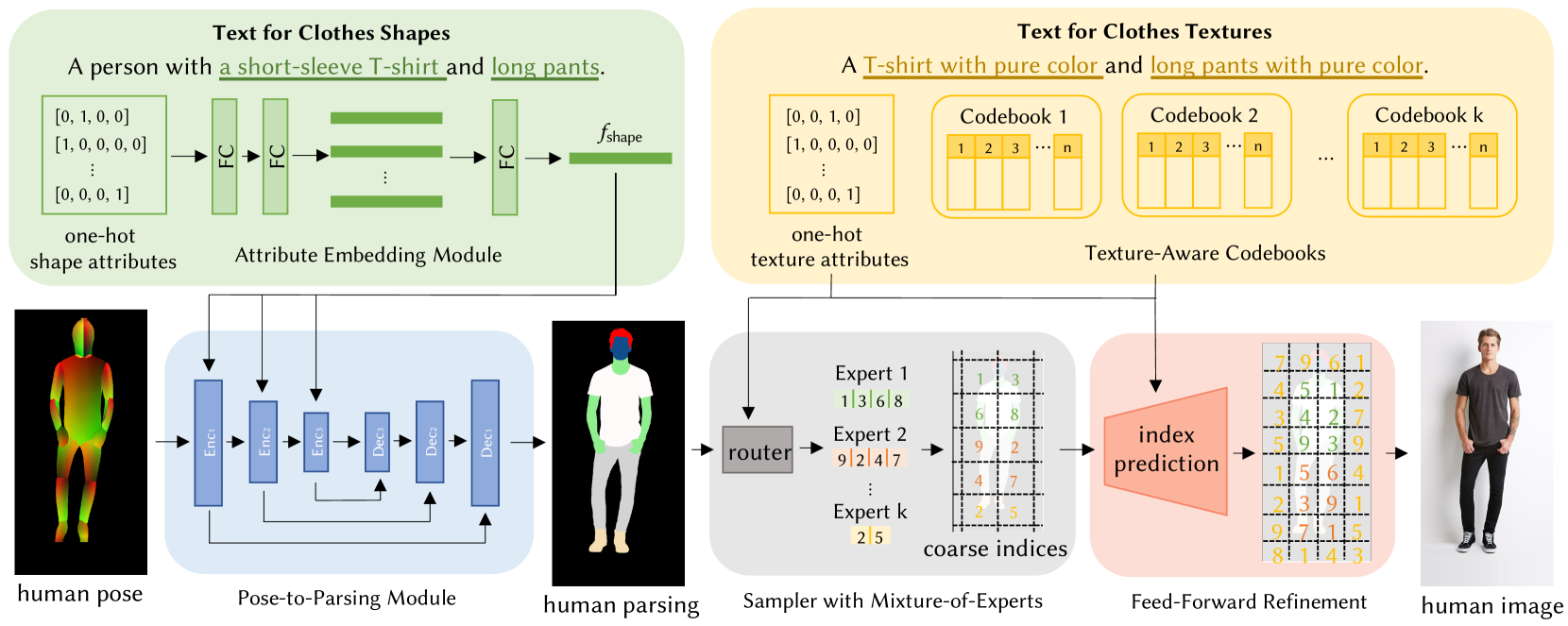
Stage I: Pose to Parsing
- Attribute Embedding Module
- 入力:clothes shapesのOne-hotベクトル
- 出力:$f_{shape}$
- フィードフォワードネットワーク
- Pose-to-Parsing Module
- Encoder-Decoderネットワーク
Stage II: Parsing to Human
- VQVAEがベース
- コードブックから画像をサンプリングするために、先行研究で使われていた自己回帰モデルではなく、拡散モデルを使用。以下のようなメリットがある
- グローバルかつ双方向の文脈に基づいて指標を予測でき、一貫性のあるサンプリング画像が得られる
- 並列に実行できるため、高速なサンプリングが可能
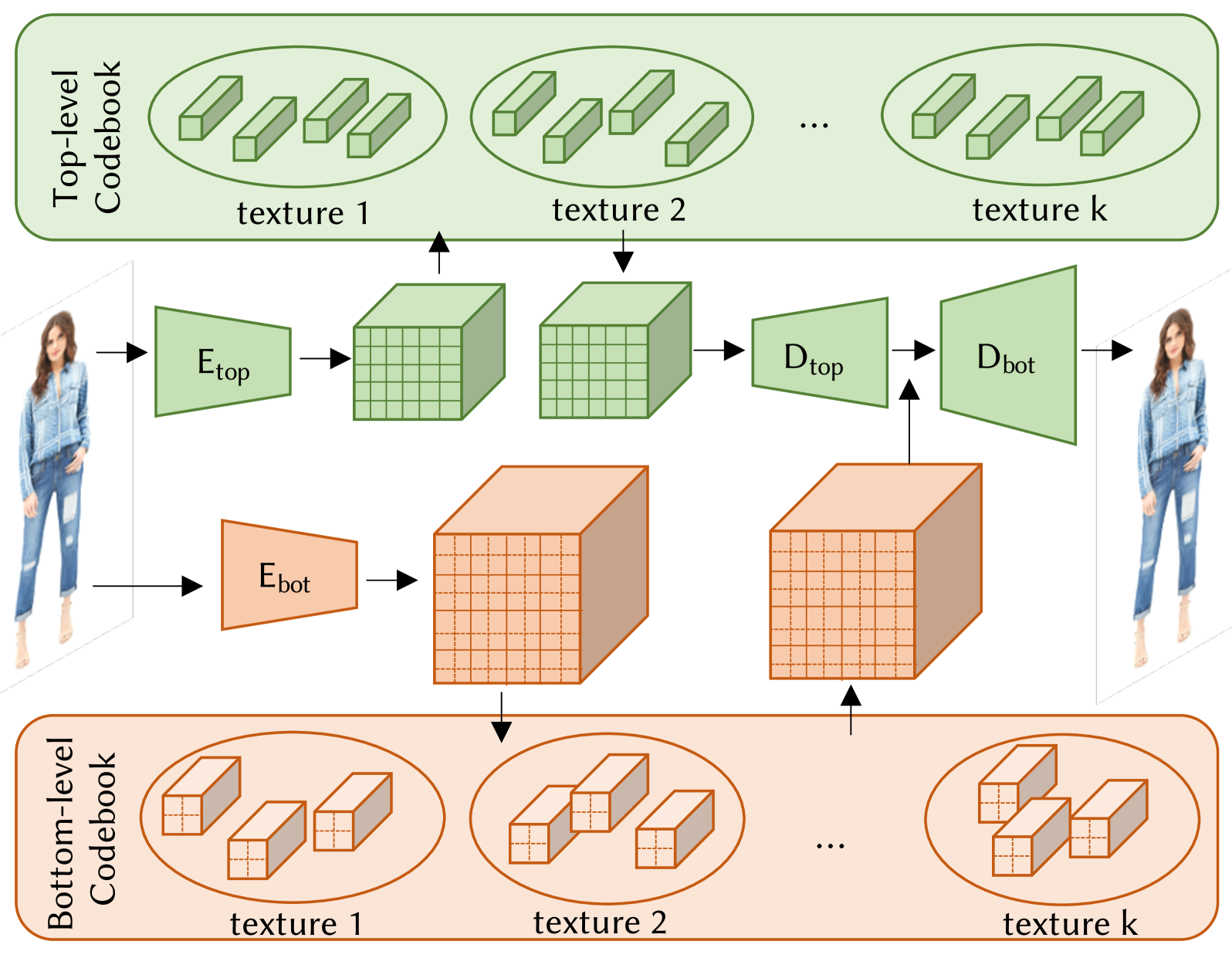
Sampler with Mixture-of-Experts
拡散モデルにmixture-of-experts(Shazeerら、2017)のアイデアを導入
- コードブックインデックス
- トークン化されたヒューマンセグメンテーションマスク
- トークン化されたテクスチャマスク
- テクスチャマスクは,衣服のテクスチャ属性ラベルをセグメンテーションマスクの対応する領域に対応させることで得られる
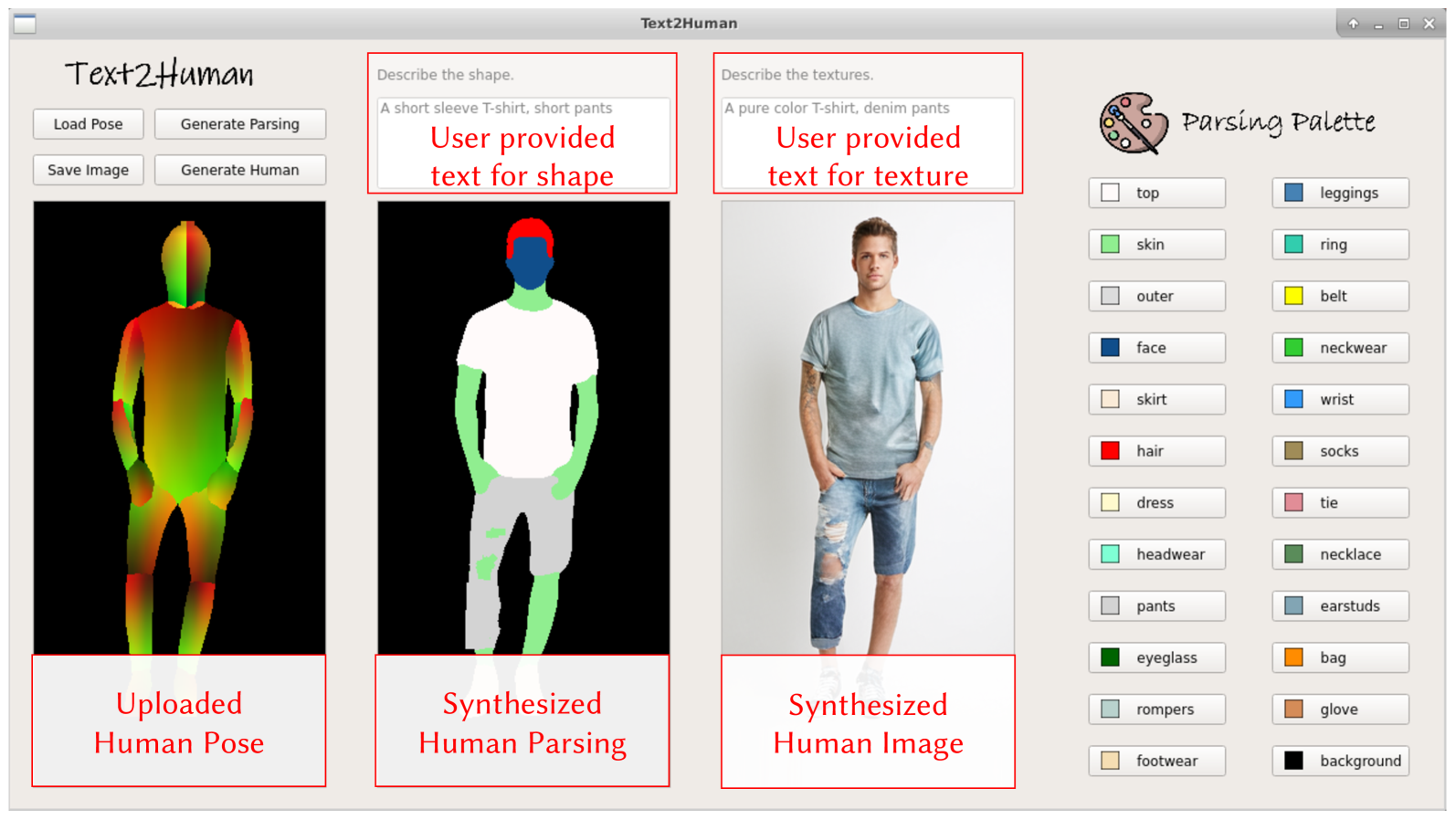
インタラクティブなUI
定量・定性指標
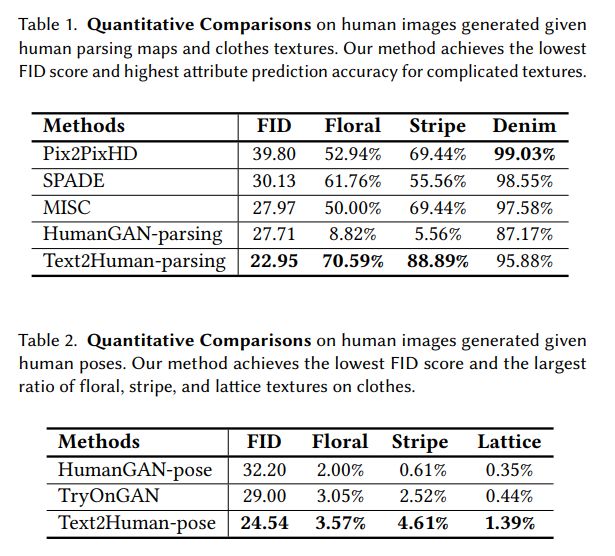
Pix2Pix2HDやSPADEはかなり前の研究。直近の先行研究のHumanGAN-poseやTryOnGANに対して良好な評価を示している。


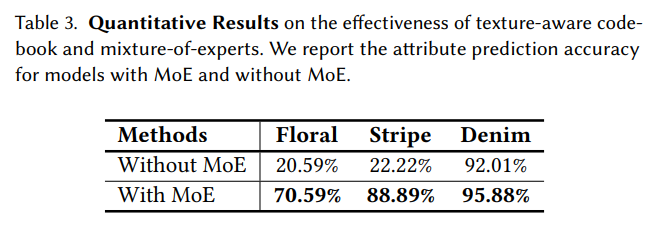
従来の研究よりも、服のテクスチャに対して強くなった。Stage IIのネットワーク構造に工夫が入っているのが大きく、「mixture-of-experts」を外すと大きく悪化する。
なお、テキストからの合成には言語モデルとして「Sentence-BERT」を使うのみで、CLIPのような画像-テキストの同期は行っていない。
感想
- Vision & Languageのフレームワークでありながら、CLIP特徴量を使わずに、BERTとVQVAEでやってるのが面白い
- 生成モデルは細かなテクスチャが苦手なイメージがあったが、VQVAEがベース+Mixture of Expertsを使うとかなりうまくいくのが驚き
- コードや訓練済みモデルがMITライセンスで公開されているのが素晴らしい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー