
論文まとめ:One-Shot Adaptation of GAN in Just One CLIP


目次
引用
- タイトル:One-Shot Adaptation of GAN in Just One CLIP
- 論文:https://arxiv.org/abs/2203.09301
- コード:https://github.com/submission6378/OneshotCLIP
- デモ:https://colab.research.google.com/drive/1Qqp3gRYArnY4pY6Am_aI9l_EOwXgxf9j?usp=sharing
ざっくりいうと
- 訓練済みCLIPとStyleGANを使ったOne-shot Domain Adaptation GAN(スタイル変換に近い)。
- Source-Targetの画像全体やパッチ間の、CLIP空間での類似度を学習する正則化を提唱し、One-shot下でおこるオーバーフィッティング/アンダーフィッティングの解消に貢献
- フレームワークはそのままで、損失関数を変更すればテキストベースのTargetも可能

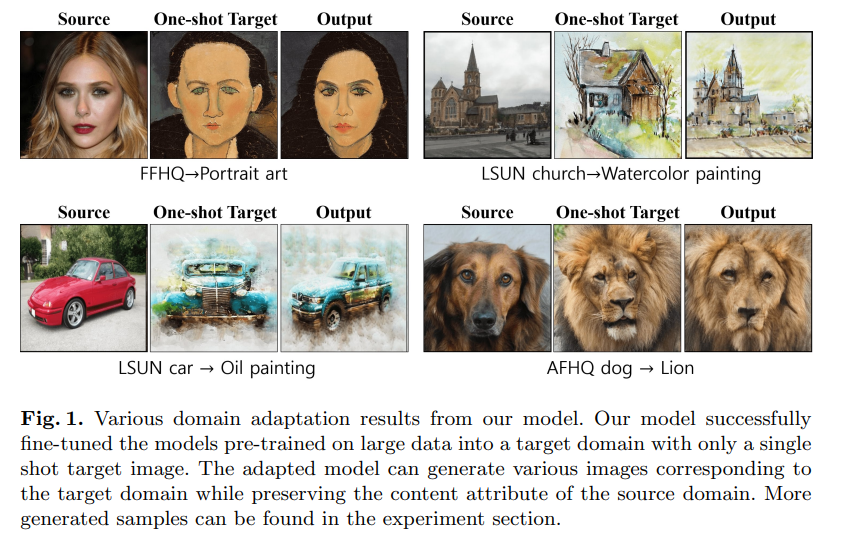
本研究の概要
背景
これまでの流行り手法:事前学習したGを少数のターゲット画像でfine-tuning
- 初期の手法:100枚の画像でfine-tuning
- その後、10枚でGANのDomain-adaptationが可能
- 最近はOne-shotの手法ができつつある
ただ、One-shotはオーバーフィッティングやアンダーフィッティングにより、生成性能が著しく低下する
CLIP空間の操作
ここが本研究の新しい手法。CLIP空間において$I_{ref}$と$I_{trg}$の間の意味的属性を整合させる戦略を提唱。具体的には2段階に分かれている。
- CLIPガイド付き潜在的最適化を用いた、ソースジェネレータにおける参照画像検索
- それに続く、ソースジェネレータと適応済みジェネレータ間の、CLIP空間整合性を課す新しい損失関数によるジェネレータのfine-tuning
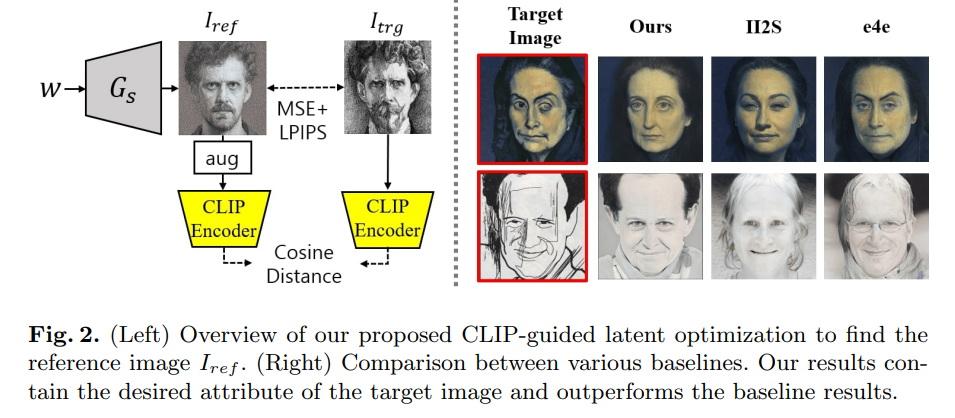
CLIP空間操作戦略により、より効果的な属性編集が可能になった
第一段階:参照画像に一致する潜在空間変数の探索
アウトライン
与えられたターゲット画像$I_{trg}$に最も似ている画像を、事前学習したソースジェネレータから見つけ、参照画像$I_{ref}$として使用したい。
具体的には、参照画像に一致する生成画像$I_{ref}=G(w_{ref})$を探索する
- CLIP空間の類似性の探索は性能を著しく向上させる
- 後続のfine-tuningフェーズの$I_{trg}$のアライメントをとりたい
- 具体的には、fig3(a)のようにCLIP空間の類似度分布を維持することで、生成画像の意味情報を考慮
詳細
こういうのはぱっと見GAN inversionでできそうだが、実はそれが限界がある。
$I_{trg}$のドメイン(例:ラフスケッチ)が、ソースドメイン(例:FFHQ)から離れている場合、既存の反転モデルでは$I_{trg}$の属性を再構築できない
→ ブルートフォース的な探索をする

$D_{CLIP}$がCLIP空間でのコサイン距離。
第二段階:パッチ単位、グローバルなDを使ったfine-tuinng
アウトライン
次にやりたいこと:$I_{trg}$のドメイン情報をもったジェネレータ$G_t$となるようにfine-tuneする
ゴール:前のステップで得られた$I_{ref}$と$I_{trg}$のアラインメントをとり、Gsの多様なコンテクスト属性を保持した$G_t$を作る
第2段階では、パッチ単位のDとグローバルのDを用いる。
- ステップ1と同様に、CLIP空間の正則化によって問題が解決
- 前段階で得られた$I_{ref}$が、ソースジェネレータの主要な属性情報(コンテンツ形状など)を維持するように、適応ジェネレータを導く参照点として重要な役割を果たす
- ソースとターゲットの領域整合性をさらに一致させるために、生成されたサンプル間のCLIP空間関係を維持する新しい整合性の損失関数を提案
- CLIP空間におけるContrastive Learningによりパッチ単位の意味関係を保持
従来の研究では、生成元と生成先の特徴量の分布を一致させることが試みられている。しかし、One-shotの条件下では、このような生成器特徴の分布に基づく正則化は機能せず、依然としてオーバーフィッティングの原因となる。
詳細
第二段階は3つの損失関数からなる
CLIP空間でのSource-Tragetのペア類似度を求めるLcon
Fig.3の(a)

CLIPのL2回帰をする(KLダイバージェンスだと訓練の安定性が損なわれる)。
パッチ単位の意味的整合性をとるLpatch
Fig.3の(b)
- ランダムなパッチ単位でCLIPの特徴量をとる
- SourceとTargetで、座標が同一の領域は正、座標が異なる例は負として認識。これらのコサイン距離を学習するような損失関数$L_{patch}$を定義し、Contrastive Learningをする
- 数式内のs0はパッチ領域を示す

基準ターゲットのアライメントをとるLref
GANでありがちなロス構成
- ピクセル単位の「L2」
- 「LPIPSベース」のロスと
- Adversarial Loss
全体の損失関数
- 画像ペア単位のCLIP空間上でのコサイン類似度の損失関数:Lcon
- パッチ単位の損失関数:Lpatch
- L2やLPIPSや敵対的損失:Lreg

Adversarial Lossの部分はStyleGAN2のロスがベース。$D_{glob}$にStyleGAN2の訓練済み係数を使用。
実験
- 訓練済みStyleGAN2を使用。FFHQ, LSUN church, LSUN carsを使用。
- 学習時間は、RTX 20801台、2,000iter約30分。ステップ1のCLIPガイド付き最適化の3分間を含めた時間。
- 第二段階、StyleGAN2のGのto-RGB層とマッピングレイヤーの係数を固定
- wのいじり方にコツがあり、
- Step1の潜在空間のStyleGAN探索では、単一の$W\in\mathbb{R}^{512}$のみ探索している
- スタイルをミックスする際に、データセットに応じて16個のベクトル(層)の一部を置き換えている(7~9)
既存研究との比較

- Style-NADAやMIND GAPではオーバーフィッティング・アンダーフィッティングが起こっている。左の上から2番目のような、対象画像が元画像の領域と大きく異なる場合に顕著
- CLIP空間での演算が有効に機能している

CLIPoptや$L_{con}$がないとかなり大きく変わる
JojoGANもOne-shot Domain Adaptationだが、これよりもオーバーフィッティングの問題が改良されている(JojoGANと比較しているのが面白い)

参考:ジョジョのキャラクター風に顔写真を変換する「JoJoGAN」 1枚の画像からAIが学習
潜在空間の編集
潜在空間の編集はStyleCLIPにならったやりかたで、
- Sourceの画像に対応する潜在的なコード$w$がある場合、StyleCLIPでそれを操作して編集したコード$\hat{w}$を得る
- そのコードを、fine-tuningされたジェネレータ$G_t$の入力とする

テキストをターゲットとした合成

別途損失関数を定義する。本文中のAppendixp.16-17に詳しい理論が載っている。損失関数の作り方は画像をターゲットとする場合と類似。
この手法の限界
- 訓練済みのStyleGANに大きく依存している
- BigGANのような多様な自然画像を生成するGANで本手法が適用できるかは不明
- CLIPによる正則化が拡散モデルや他の生成フレームワークに適用するか検証予定
結論
キーとなるアイデアは、2段階のアプローチによるCLIP空間操作。
- CLIP空間における最適化手法を提案し、ソースドメインにおいてターゲット画像と最も類似した属性を持つ参照画像を探索
- モデルの過剰適合を防ぐため、CLIP空間において、意味的整合性損失とパッチワイズ整合性損失という2種類の正則化損失を提案
実験の結果、提案手法は既存の手法と比較して、より優れた知覚品質と多様性をもたらすことが示された、とのこと
私の感想
- 訓練済みCLIPとStyleGANを使ったfine-tuningという、今の流行りな内容だが「ここまで面白いことできるのか」と素直に感心した
- 画像に対してテキストからスタイルを転移させるのが個人的には新鮮
- 理論的には割りとシンプルなのに、JojoGANのアップデートポジションなのが面白い
- CLIPもStyleGANも1から訓練すると大変なモデルだが、訓練済みモデルからOne-shotGANするだけなら、GPU1枚で30分とお手軽なのが◎
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー