
Pandasのpivotを使ってデータを集計し、横並びの棒グラフで表示する方法
Posted On 2018-08-26


Pandasのデータフレームを集計して、横並びの棒グラフで表示したいときがあります。その方法を紹介していきます。Pivotを使うと簡単にできます。
目次
データ例
以下のようなデータ(rain.txt)があったとします。都市別(那覇、東京、札幌)の月別の平年降水量のデータを取ったものです(気象庁より)。タブ区切りテキストです。こちらからダウンロードできます。
City Month Rain
Naha 1 107
Naha 2 119.7
(中略)
Tokyo 1 52.3
Tokyo 2 56.1
(中略)
Sapporo 1 113.6
Sapporo 2 94
(中略)
これをrain.txtと保存しておきます。これを、月を横軸、降水量を縦軸として、都市別の横並びの棒グラフで表示します。
Pivotを使おう
ピボットというとExcelを思い出して頭が痛くなってくる方もいらっしゃるかもしれませんが、Pandasの場合明瞭でわかりやすいです。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("rain.txt", sep="\t")
pivot = df.pivot(index="Month", columns="City")["Rain"]
pivot.plot.bar(figsize=(10,5), title="Rainfall in Japan")
plt.ylabel("mm")
plt.show()
このdf.pivotのところがポイント。indexが表の縦軸、columnsが表の横軸となります。項目が複数あるときはスライスで表示したい項目を選びましょう(ここでは”Rain”)。内部的にはこのような表を作っていることになっています。
print(pivot)
City Naha Sapporo Tokyo
Month
1 107.0 113.6 52.3
2 119.7 94.0 56.1
3 161.4 77.8 117.5
4 165.7 56.8 124.5
5 231.6 53.1 137.8
6 247.2 46.8 167.7
7 141.4 81.0 153.5
8 240.5 123.8 168.2
9 260.5 135.2 209.9
10 152.9 108.7 197.8
11 110.2 104.1 92.5
12 102.8 111.7 51.0
「indexが縦、columnsが横」と覚えればとても直感的でわかりやすいですね。このようなグラフができます。
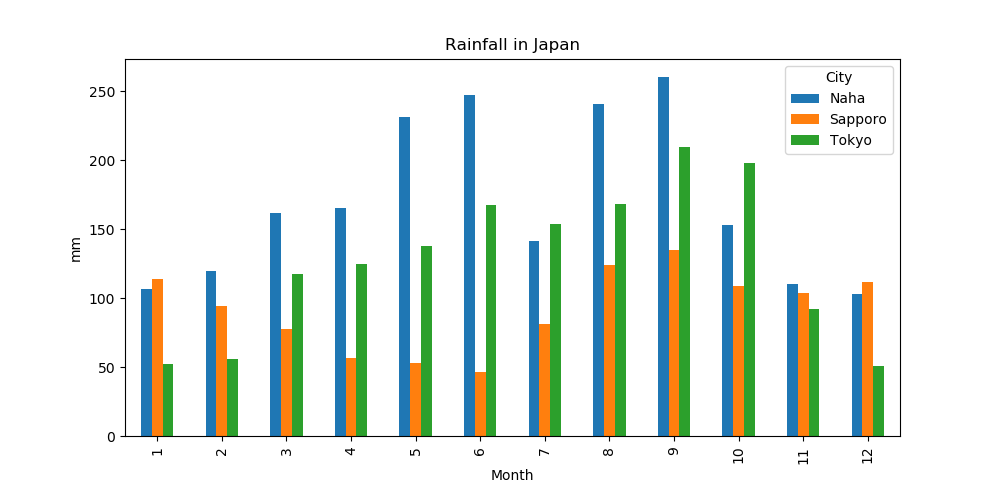
「plot.bar」の引数でpyplot側のパラメーターも操作できます。例えばfigsize(グラフサイズ)や、title(グラフタイトル)がそうです。ylabelは引数として与えようとするとエラーが出てしまったので、後から「plt.ylabel」で与えています。
以上です。Pivotを怖がらずに上手く使ってグラフを素早く書いてみてくださいね。
参考
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー